
Оригинал: Self-Hosting AI Models
Перевод для канала Мы ж программист
Привет, разработчики! В сегодняшней статье я расскажу о том, как вы можете самостоятельно развернуть модели искусственного интеллекта на своем компьютере и начать использовать их бесплатно. Недавно я искал инструмент, который помог бы превратить мою локальную систему в сервер искусственного интеллекта, и нашел нечто потрясающее. Я подробно расскажу о том, как начать им пользоваться, упростить себе жизнь, проводить больше экспериментов с ИИ и многом другом.
Почему собственный хостинг?
Это первый вопрос, который возник у нас, когда мы решили использовать ИИ с самостоятельным развертыванием. Вот несколько ключевых моментов, которые я учитываю перед тем, как развернуть ИИ-модели самостоятельно:
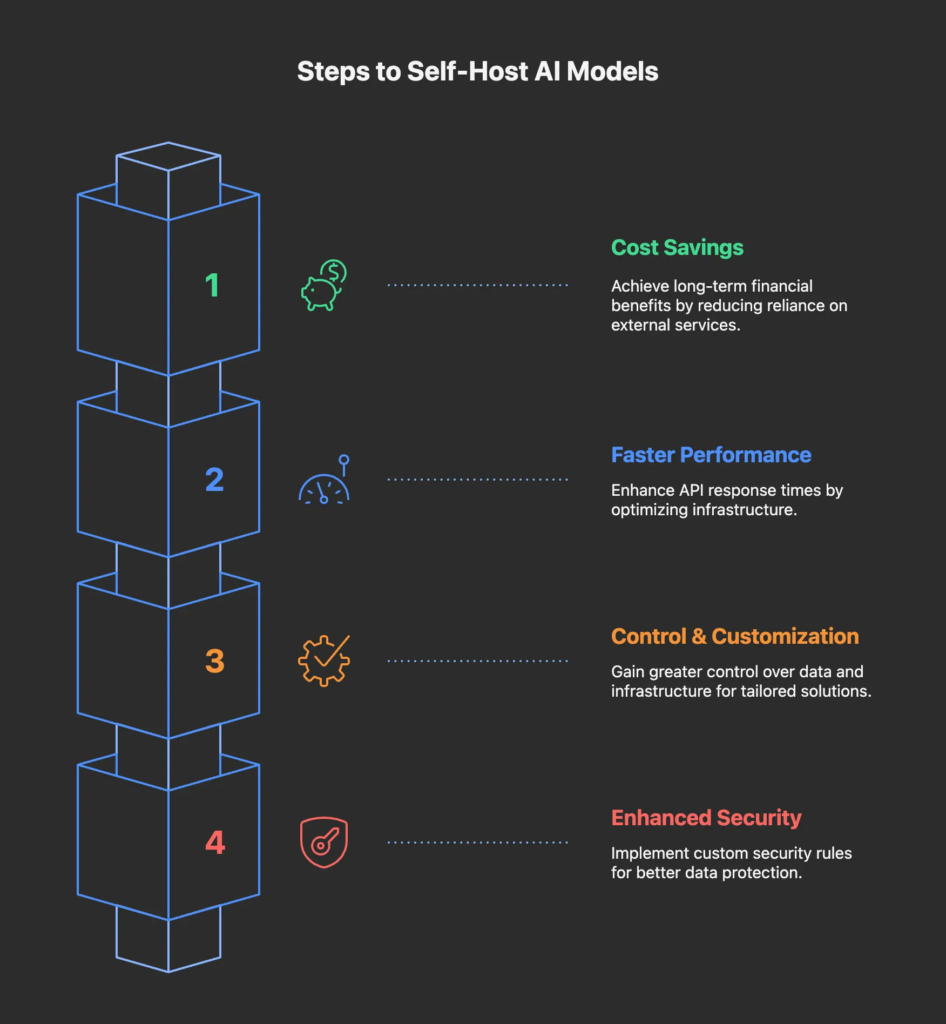
- Экономия средств: ИИ с самостоятельным развертыванием может потребовать значительных начальных затрат, но в долгосрочной перспективе позволяет сэкономить значительные средства.
Более высокая производительность: обеспечив надлежащую инфраструктуру, вы можете сократить задержку при работе ваших API. - Контроль и настройка: самостоятельно размещенный ИИ обеспечивает лучший контроль над инфраструктурой и данными для создания индивидуальных решений.
- Безопасность: он обеспечивает более высокий уровень безопасности за счет настройки правил и лучшего контроля над данными.
Как самостоятельно развернуть ИИ?
Итак, вот главный вопрос: как самостоятельно развернуть ИИ на локальном компьютере?
Я использую инструмент под названием OLLAMA для самостоятельной развертки ИИ, и, поверьте, начать с ним работать очень просто. Вам просто нужно скачать OLLAMA на свою локальную систему с помощью исполняемого файла Docker, и вуаля — вы готовы использовать свой новый сервер ИИ, размещенный на собственном хостинге. Позвольте мне показать вам, как это сделать.
- Посетите их сайт, чтобы скачать Ollama — https://ollama.com/download
- Чтобы установить его с помощью Docker, следуйте следующим инструкциям:
Запуск только на CPU:
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaС использованием GPU:
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollamaБольше деталей тут https://hub.docker.com/r/ollama/ollama
Теперь вы успешно установили Ollama в своей системе и почти готовы к работе. Давайте рассмотрим дальнейшие шаги.
Теперь вы можете проверить, запустив команду ollama в терминале:
или посетив адрес localhost:11434 в браузере:
Загрузите любимую модель
Ollama предоставляет возможность загрузить и использовать любую понравившуюся модель искусственного интеллекта. Чтобы загрузить модель, необходимо перейти в репозиторий моделей и выбрать ту, которую вы хотите запустить.
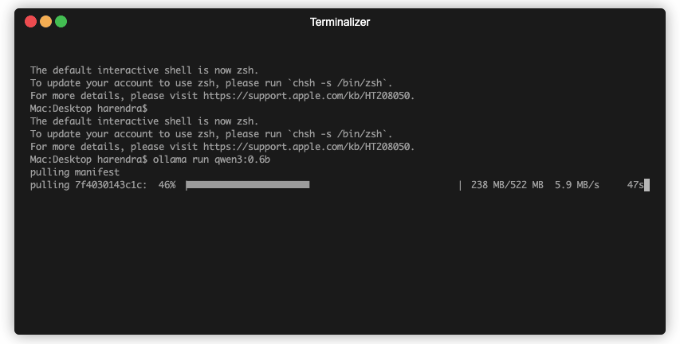
Например, я загружу модель qwen3:0.6b, выполнив следующую команду, чтобы получить её и начать использовать:
ollama run qwen3:0.6bВ первый раз модель будет загружена (это займет некоторое время), после чего она будет доступна в вашей системе, и вы сможете использовать её в любое время:
Используйте ollama list, чтобы просмотреть все загруженные модеи:
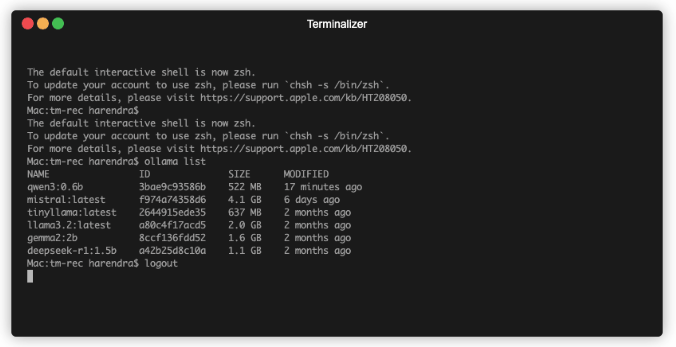
Как только загрузка модели завершена, можете начинать ее использовать в терминале:
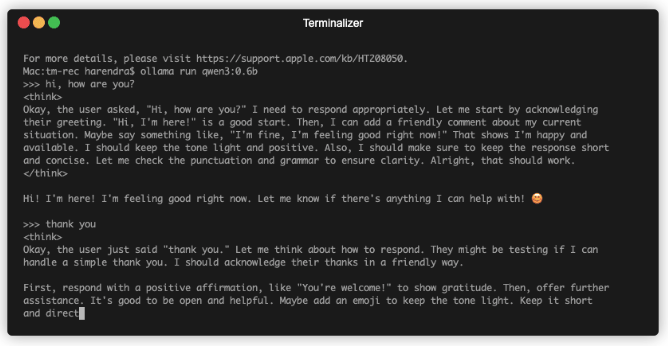
Ollama API
Мы убедились, что успешно установили OLLAMA в нашей системе, но использовать его через терминал не предполагается. Нам нужно интегрировать его в наш код. Здесь Ollama предоставляет поддержку OpenAI SDK, что позволяет начать работу с ним, просто настроив нужный конечный пункт и модель. Давайте разберемся в этом на примере кода. Я приведу пример кода на Go.
package main
import (
"context"
"github.com/openai/openai-go"
"github.com/openai/openai-go/option"
)
func main() {
client := openai.NewClient(
option.WithAPIKey(""),
option.WithBaseURL("http://localhost:11434/v1"),
)
chatCompletion, err := client.Chat.Completions.New(context.TODO(), openai.ChatCompletionNewParams{
Messages: []openai.ChatCompletionMessageParamUnion{
openai.SystemMessage("You are a helpful assistant."),
openai.UserMessage("Who won the world series in 2020?"),
},
Model: "qwen3:0.6b",
})
if err != nil {
panic(err.Error())
}
println(chatCompletion.Choices[0].Message.Content)
}Вывод:
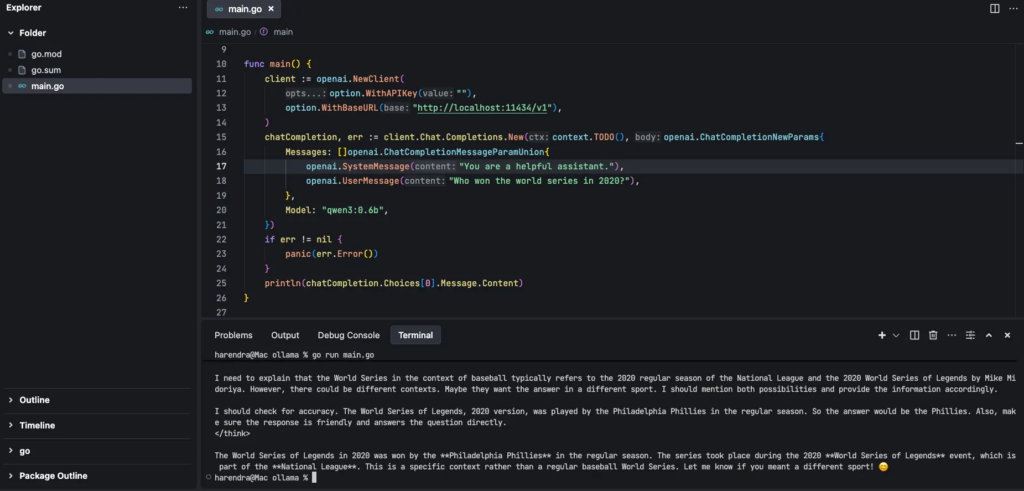
Также вы можете использовать curl-запрос, чтобы убедиться, что API работает корректно:
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3:0.6b",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'Заключение
Я рассмотрел практически все важные этапы, необходимые перед тем, как приступить к развертыванию ИИ на собственном хостинге. Я скажу, что если у вас есть долгосрочная перспектива использовать ИИ в широких масштабах, то вам будет очень полезно самостоятельно развернуть модели ИИ. Я уделяю больше внимания использованию технологий с открытым исходным кодом.