
Оригинал: System Design Interview: Design Twitter (X)
Перевод для канала Мы ж программист
В этом примере собеседования по проектированию систем мы разберем дизайн приложения, похожего на Twitter, включая все шаги от начальных требований до высокоуровневой архитектуры.
Начнем с уточнения функциональных и нефункциональных требований и заложим основу для нашего дизайна. Затем набросаем высокоуровневый дизайн API, а за ним высокоуровневый дизайн всей системы.
Предыстория
Начнем с предыстории Twitter (теперь X).
Люди могут подписываться на других, и это может быть взаимно, что значит, что другие могут подписываться на них в ответ.
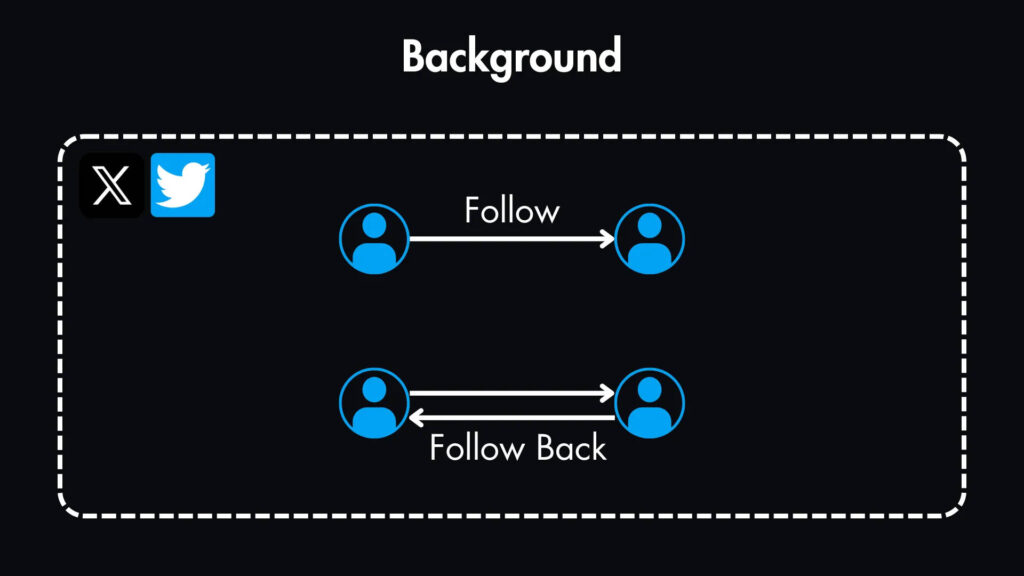
Но, естественно, у некоторых пользователей окажется больше подписчиков, чем у других.
Это говорит о том, что система будет интенсивно читать, поскольку большинство пользователей только просматривают твиты, в то время как меньший процент будет активно создавать твиты.
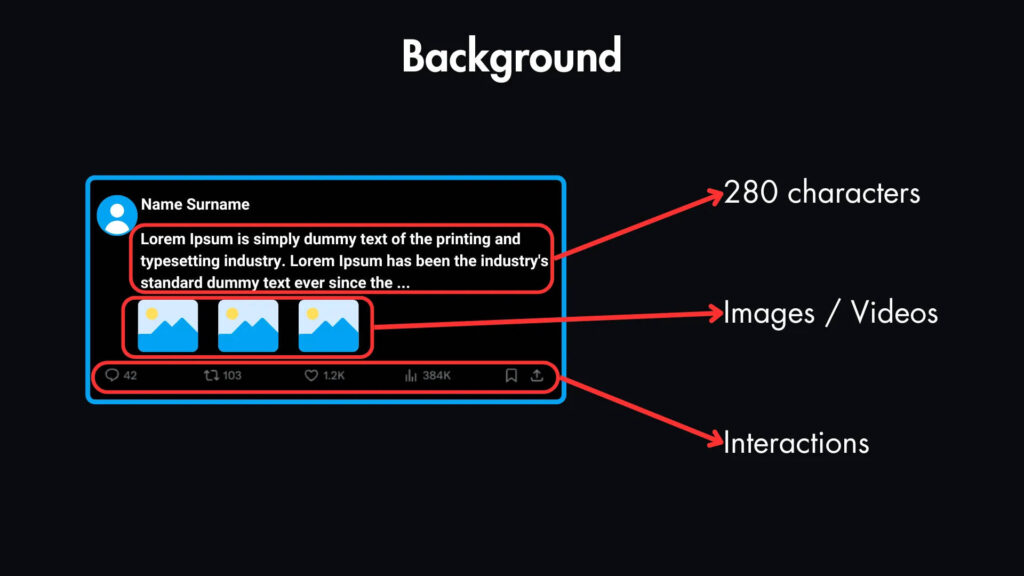
Типичный твит может содержать до 280 символов текста, а также может включать изображения или видео.
Внизу каждого твита есть интерактивные элементы, позволяющие пользователям ставить лайки, комментировать, ретвитить и подписываться на других пользователей.
Функциональные требования
Давайте расставим приоритеты по этим функциям. Наши обязательные функции для этой системы:
- Подписка (following): пользователи должны иметь возможность подписываться на других пользователей.
- Твиты: пользователям необходимо создавать твиты. Твиты могут включать текст (до 280 символов для большинства пользователей), изображения и видео. (Мы не будем включать премиум-функцию расширенной длины твита в этот базовый дизайн).
- Лента новостей: пользователи должны видеть твиты пользователей, на которых они подписаны. Мы сосредоточимся на этом типе ленты в нашем дизайне, хотя стоит отметить, что такие платформы, как X, теперь также предлагают алгоритмическую ленту «For You».

Нефункциональные требования
Теперь давайте рассмотрим требования к масштабу и производительности, которые должна удовлетворять эта система.
Масштаб
Исследования показывают, что в настоящее время у X 500 миллионов активных пользователей в месяц (MAU). Предположим, что из этих 500 миллионов MAU, 200 миллионов — это активные пользователи в день (DAU).
Средний пользователь обычно следит за 100 аккаунтами. В среднем каждый пользователь создает 10 твитов в день и читает 100 твитов.

Используя эту информацию, мы можем рассчитать объемы чтения и записи.
Объем чтения: При нашем предположении, каждый DAU читает в среднем 100 твитов в день. Это около 200 млн * 100 = 20 миллиардов операций чтения ежедневно.
Объем записи: если каждый DAU создает в среднем 10 твитов в день, это составляет 200 млн * 10 = 2 миллиарда новых твитов ежедневно.

Размер данных
Размер каждого твита может быть в среднем 1 КБ, если он только текстовый. Если он содержит вложения, такие как изображения и видео, он может варьироваться от 1 МБ до 5 МБ.
Для упрощения предположим, что средний размер твита составляет 1 МБ, хотя некоторые твиты с медиафайлами могут быть больше.
Это означает, что мы имеем дело с 200 МБ * 1 МБ = 20 петабайтами данных, считываемых ежедневно.

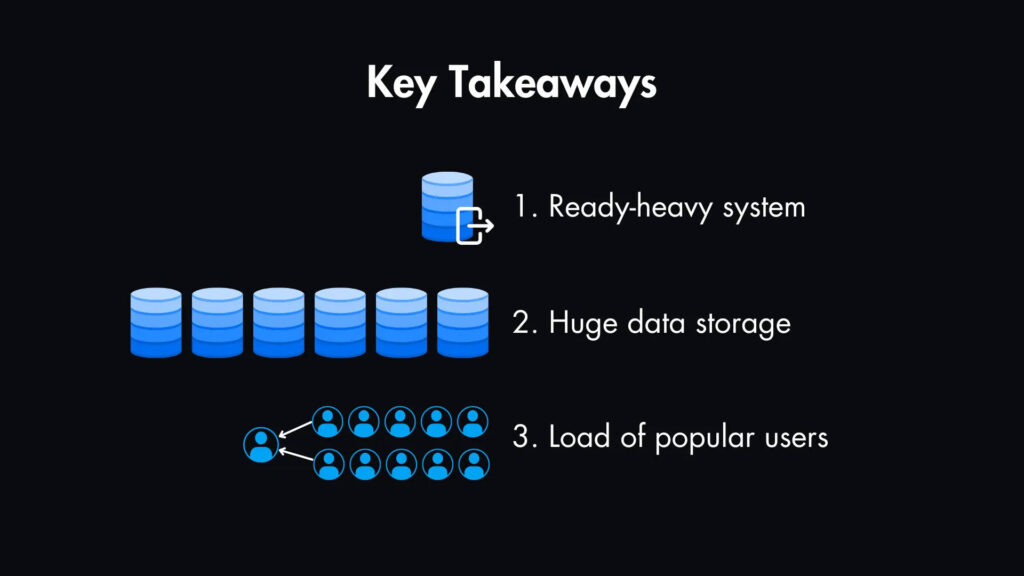
Ключевые выводы
- Очевидно, что это система с высокой интенсивностью чтения. Это значит, что мы должны оптимизировать ее для эффективного чтения.
- Требования к хранению данных огромны, поэтому нам придется рассмотреть масштабируемые решения для хранения.
- Обработка потока популярных пользователей с миллионами подписчиков представляет собой уникальную задачу.
Это подготавливает почву для разделов проектирования API и высокоуровневого проектирования системы, где мы начнем решать эти проблемы.
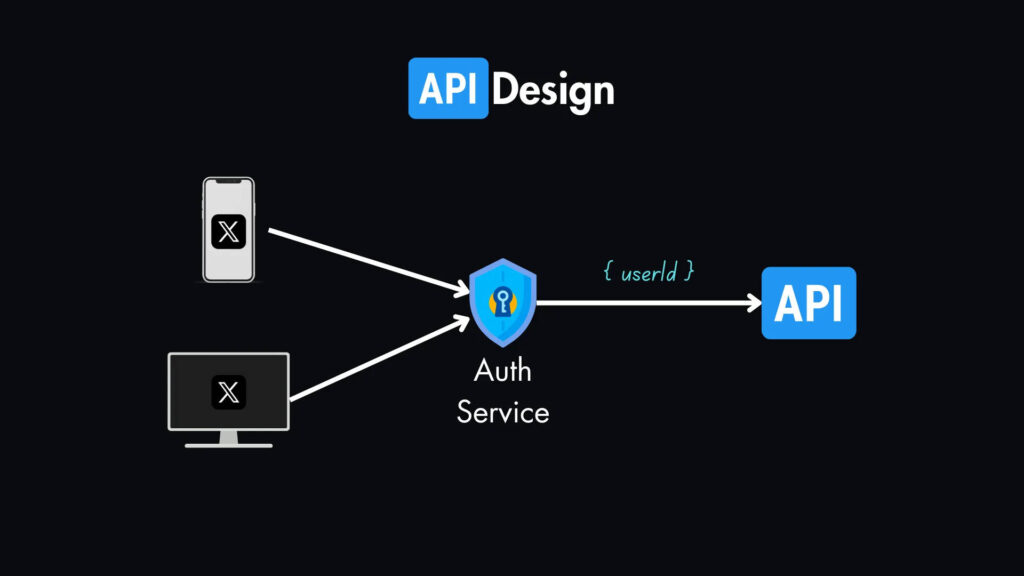
Проектирование API
Предположим, что все запросы аутентифицируются с помощью службы аутентификации перед тем, как попасть в наш API, и в каждом запросе есть userId.
Поскольку на собеседованиях по проектированию систем интервьюер обычно предполагает, что вы знаете, как работает аутентификация, то не стоит тратить время на подробное обсуждение этого вопроса.
Вот наши основные эндпоинты:
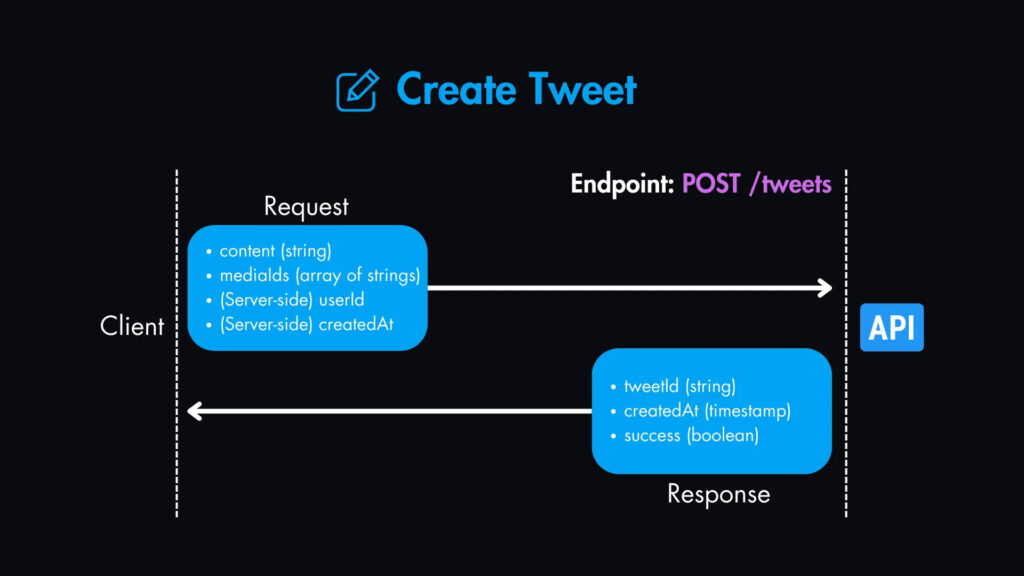
1. Создать твит — POST /tweets
Параметры запроса:
content(string): Текстовое содержимое твита.mediaIds(массив строк, опционально): Массив идентификаторов мультимедиа (для изображений, видео и т. д.).- (Server-side)
userId(string): Получено от службы аутентификации. - (Server-side)
createdAt(timestamp): Устанавливается сервером во время создания.
Содержимое ответа:
tweetId(string): Идентификатор созданного твита.createdAt(timestamp): Временная метка создания твита.success(boolean): Указывает, был ли твит создан успешно.
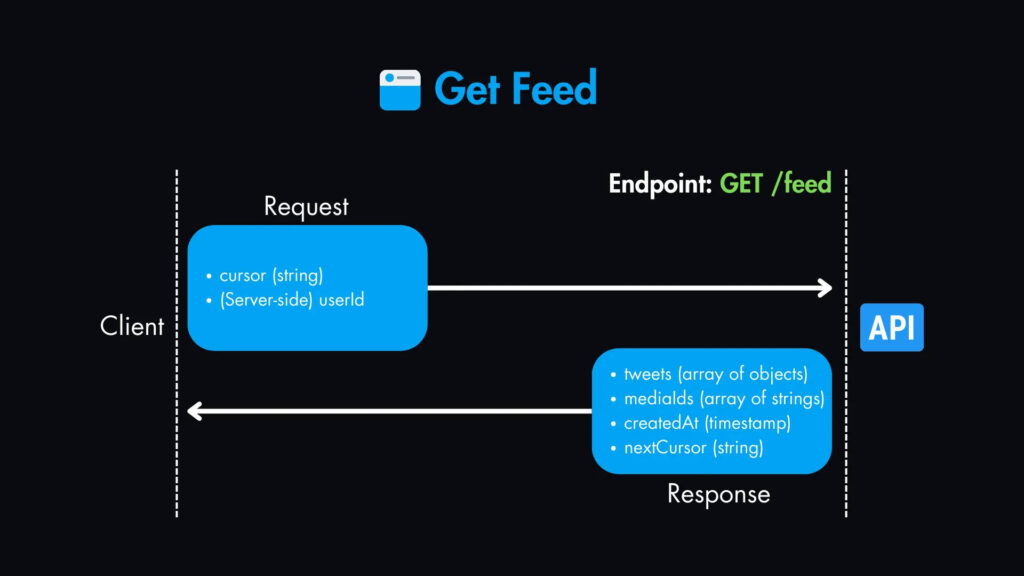
2. Получить ленту — GET /feed
Параметры запроса:
cursor(string, опционально): Токен пагинации для получения следующего набора твитов.- (Server-side)
userId(string): Получено от службы аутентификации.
Содержимое ответа:
tweets(массив объектов): Массив объектов твитов, каждый из которых содержит:mediaIds(массив строк, опционально): Массив идентификаторов медиаcreatedAt(timestamp): Метка времени создания.nextCursor(string, опционально): Токен пагинации для получения следующего набора твитов.
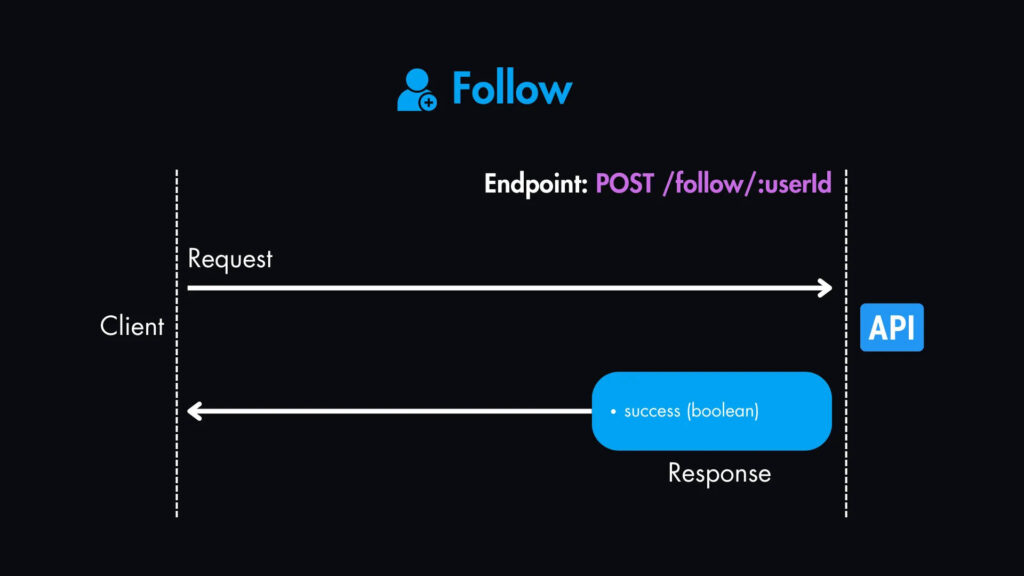
3. Подписаться — POST /follow/:userId
Параметры запроса:
userId пользователя, на которого мы подписываемся.
Содержимое ответа:
success (boolean): Указывает, была ли последующая операция успешной.
4. Отписаться — DELETE follow/:userId
Параметры запроса:
userId пользователя, от которого мы отписываемся.
Содержимое ответа:
success (boolean): Указывает, была ли операция успешной.

Примечание: если вам пока что все нравится, у меня есть бесплатный курс по проектированию систем , где вы можете узнать больше о каждом обсуждаемом здесь компоненте.
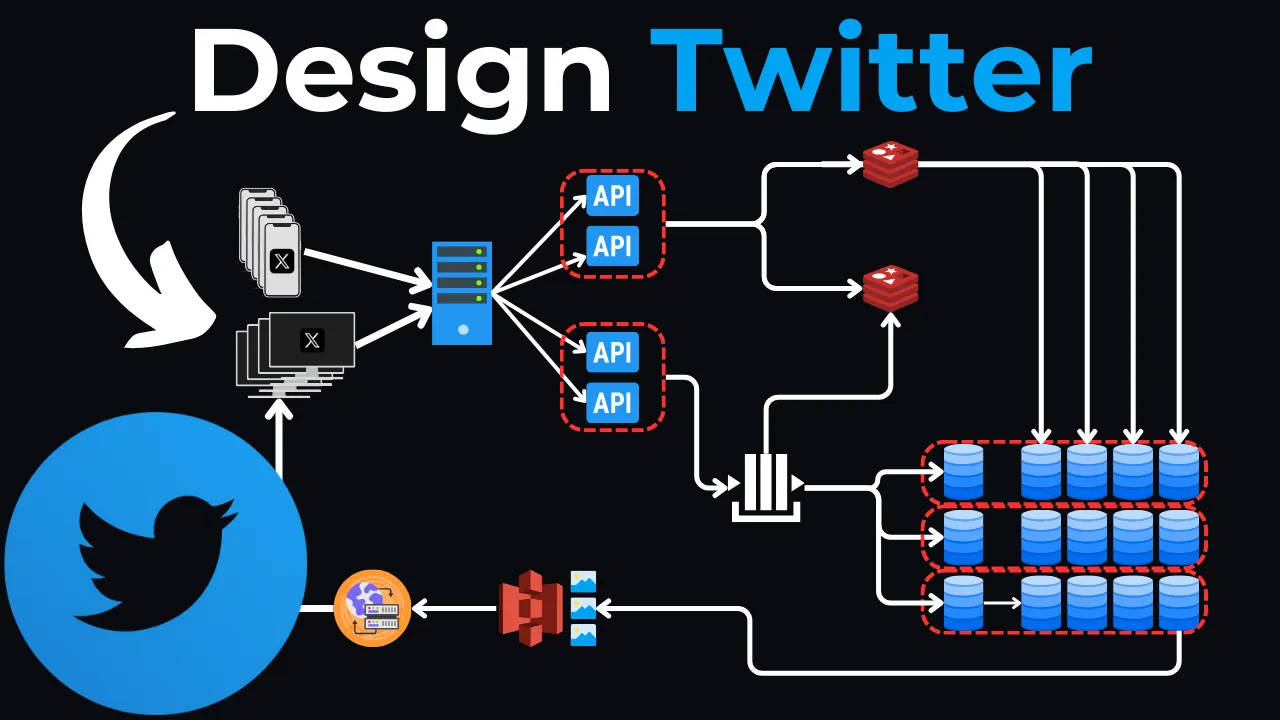
Высокоуровневый дизайн
Давайте представим себе основные компоненты этой системы:
Клиент/мобильное приложение: здесь пользователи будут взаимодействовать с системой, создавая твиты, просматривая ленты новостей и подписываясь/отписываясь от других — это может быть либо приложение браузера, либо приложение на телефонах пользователей.
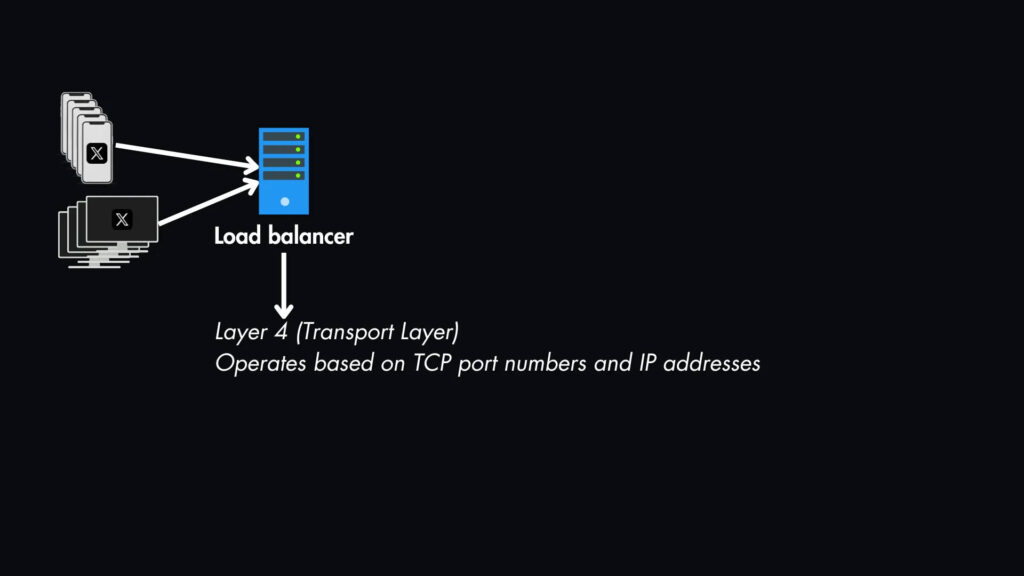
Балансировщик нагрузки: Все запросы будут проходить через наш балансировщик нагрузки, который распределяет их по нескольким серверам приложений. Это особенно важно для обработки интенсивного трафика чтения нашей новостной ленты.
На данный момент мы можем использовать балансировку нагрузки слоя 4 (транспортный слой), которая работает на основе номеров портов TCP и IP-адресов.
Это подходит для распределения общего трафика без необходимости проверки содержимого запросов. Однако вскоре мы изменим этот слой в разделе масштабирования.
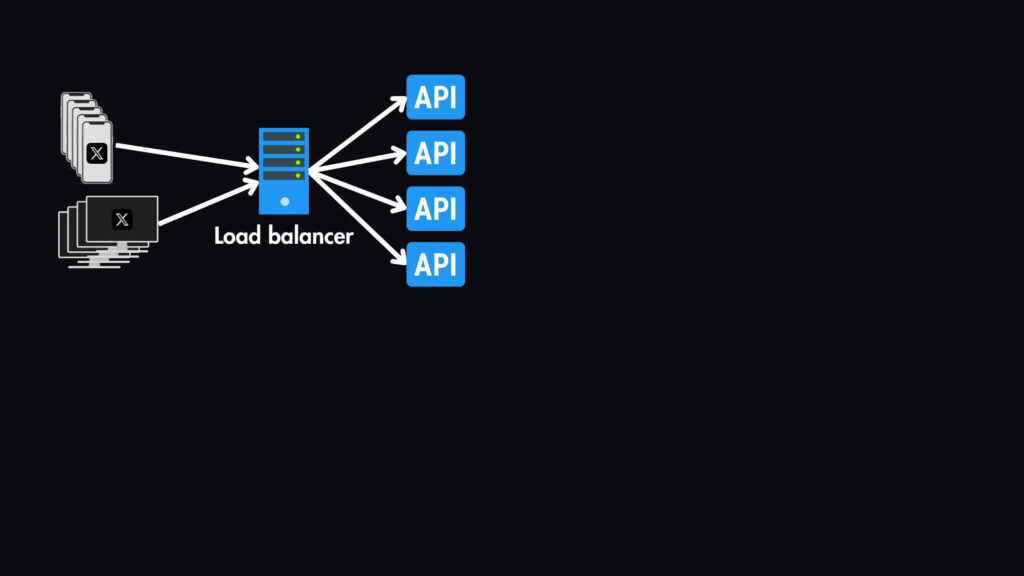
API-серверы: эти серверы обрабатывают описанные выше API-запросы, такие, как получение твитов, фильтрация каналов, взаимодействие с базой данных и кэшем, а также отправка ответов обратно клиенту.
База данных (SQL): Хотя базы данных NoSQL отлично справятся с обработкой больших объемов неструктурированных данных, реляционная база данных (SQL) лучше подходит для нашего варианта использования из-за необходимости сложных отношений и объединений между пользователями и твитами. Мы будем использовать реляционную базу данных (например, MySQL или PostgreSQL) для хранения структурированных данных.
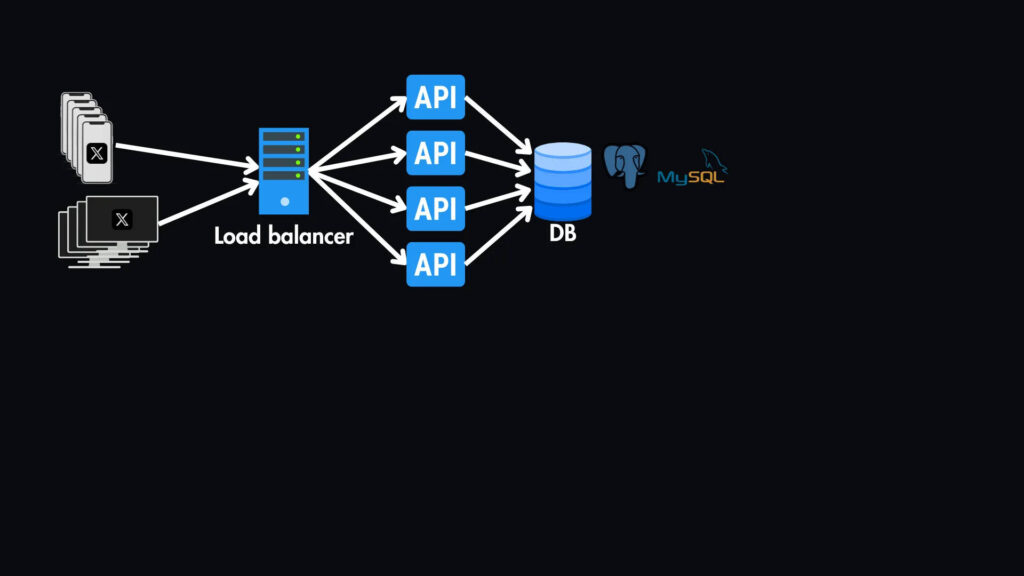
Схема базы данных
Ниже приведена базовая схема нашей базы данных.
У нас будет таблица подписчиков, в которой хранятся идентификаторы подписчика и того, на кого подписываются. Эти идентификаторы являются внешними ключами, связанными с таблицей пользователей.
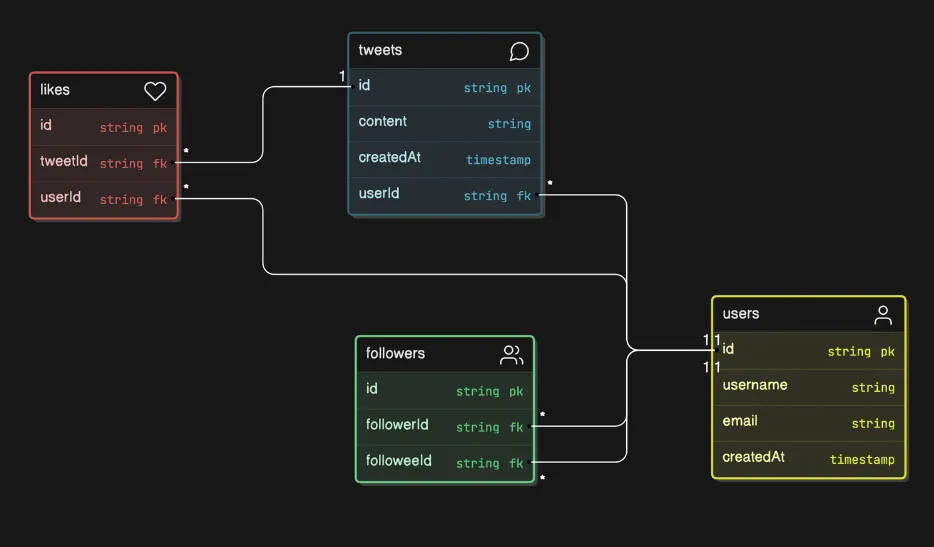
Таблица пользователей будет связана с таблицей твитов с идентификаторами пользователей. Также могут быть некоторые небольшие таблицы, такие как таблица лайков, которые хранят связь между твитами и их владельцами.
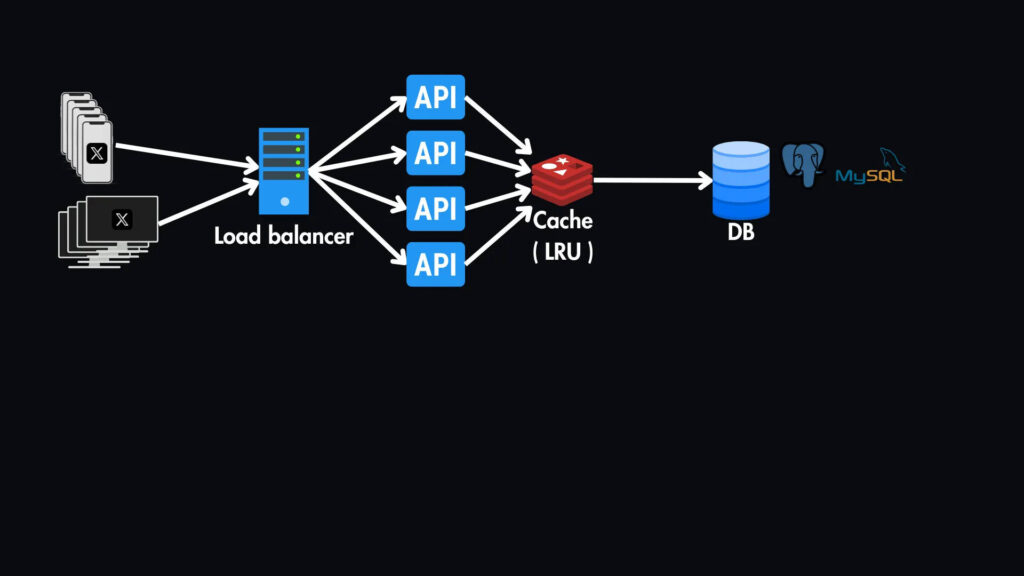
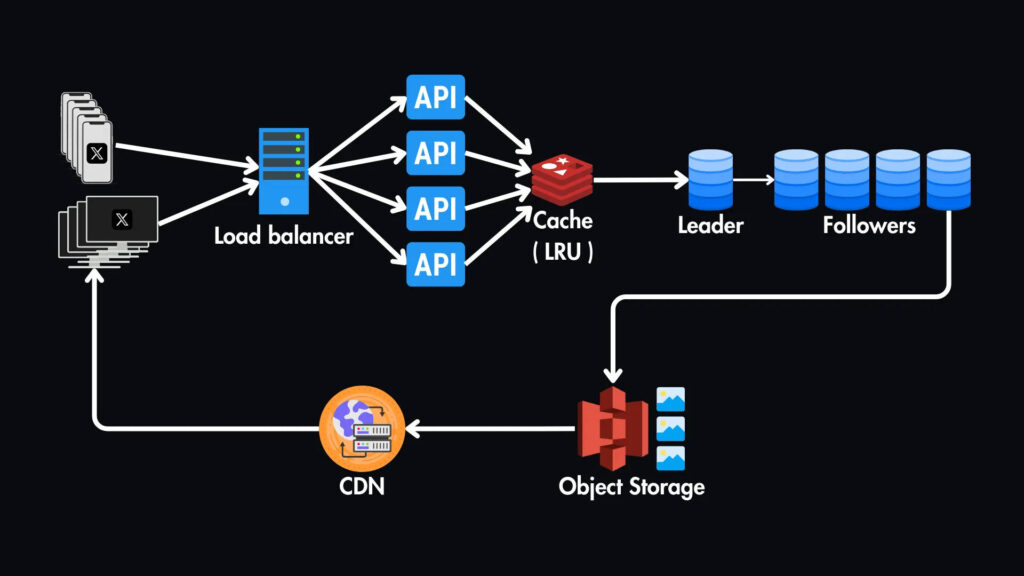
Кэширование
Возвращаясь к нашему высокоуровневому дизайну, мы будем использовать уровень кэширования (например, Redis или Memcached) перед базой данных для хранения часто используемых данных, таких как популярные твиты, профили пользователей и отношения подписчиков.
Это значительно снижает нагрузку на базу данных и снижает задержку чтения. Здесь подойдет кэш LRU (Least Recently Used) — общая политика вытеснения кэша для сохранения наиболее релевантных данных в кэше.
Хранилище объектов и CDN
Для хранения медиафайлов (таких как изображения и видео), которые можно прикрепить к твитам, мы будем использовать службу хранения объектов, например AWS S3.
А наша база данных SQL будет хранить метаданные этих медиафайлов, такие как имена файлов и URL-адреса.
Чтобы еще больше сократить задержку нашей системы, мы можем внедрить CDN (сеть доставки контента) для кэширования этих медиафайлов ближе к пользователям с учетом их географического положения.
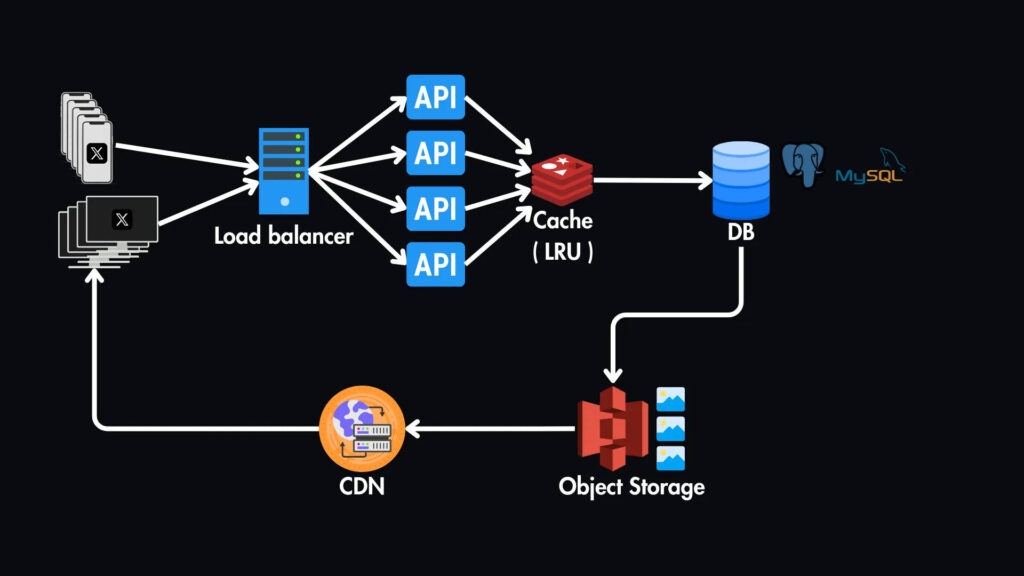
В частности, мы будем использовать CDN на основе pull-технологии, которая извлекает контент из источника (хранилища объектов) при первом запросе, а затем кэширует его для последующих запросов.
Масштабирование базы данных
База данных будет основным узким местом в нашей текущей системе, поэтому давайте рассмотрим стратегии репликации и сегментирования для масштабирования нашей системы.
Масштабирование чтения
Мы можем ввести реплики чтения нашей первичной базы данных для масштабирования чтения.
У нас будет одна главная реплика для записи и несколько реплик чтения, которые являются точными копиями главной базы данных, используемыми исключительно для операций чтения.
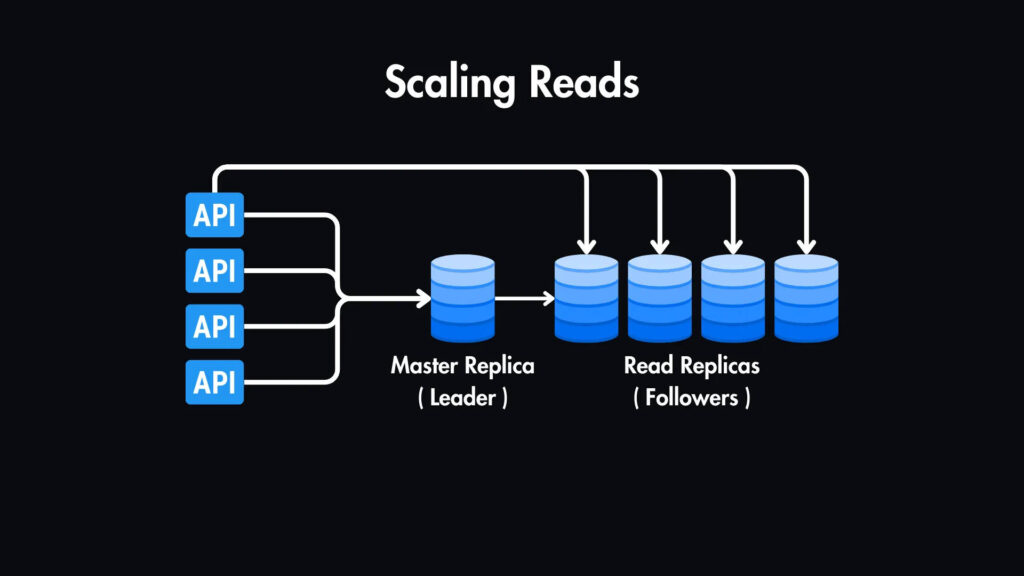
Это значительно повышает производительность чтения за счет распределения нагрузки между несколькими серверами.
Помимо чтения реплик, мы будем использовать наш слой кэширования для дальнейшего хранения популярных твитов, профилей пользователей и связей с подписчиками, что снизит необходимость запрашивать у базы данных часто используемые данные.
Масштабирование записи
Однако будут и моменты пикового трафика, и наша текущая единственная мастер-реплика представляет собой единственную точку отказа.
Чтобы масштабировать запись, мы можем разбить таблицу твитов на части на основе user_id. Это означает, что мы горизонтально разобьем таблицу на несколько серверов баз данных (shards). Каждая часть будет хранить твиты для определенного диапазона идентификаторов пользователей.
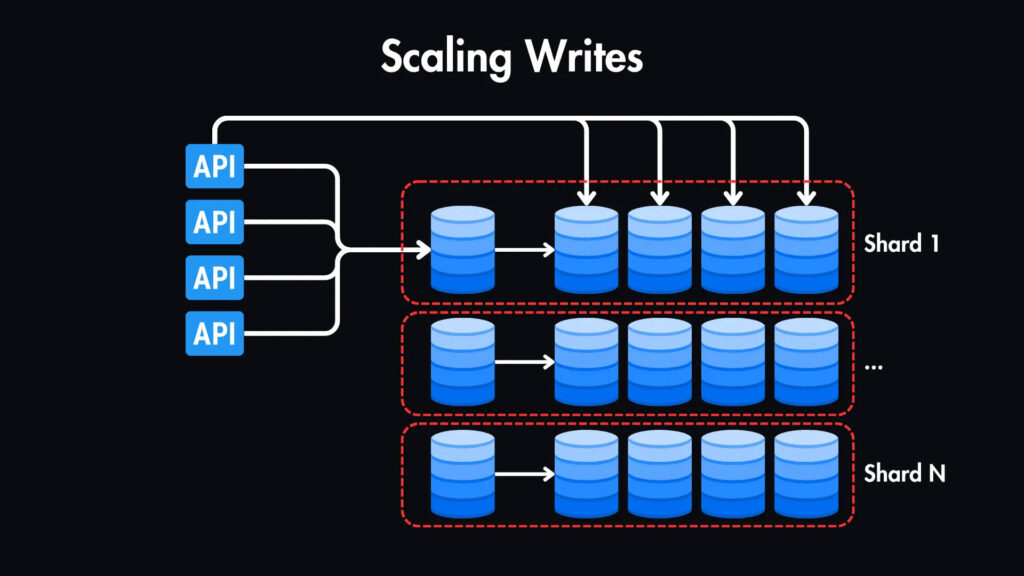
Мы будем использовать такую технику, как последовательное хеширование, для сопоставления идентификаторов пользователей с шардами, чтобы обеспечить равномерное распределение данных и минимизировать влияние добавления или удаления шардов.
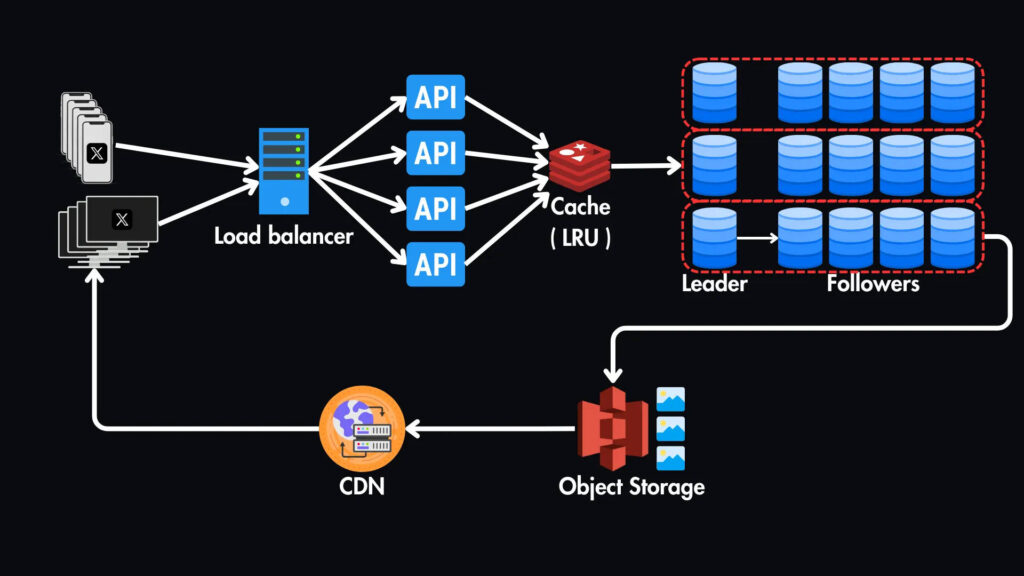
Отдельные API чтения/записи
Мы можем разделить операции чтения и записи наших API для дальнейшей оптимизации производительности.
Балансировщик нагрузки может направлять запросы на чтение в API чтения, а запросы на запись — в API записи.
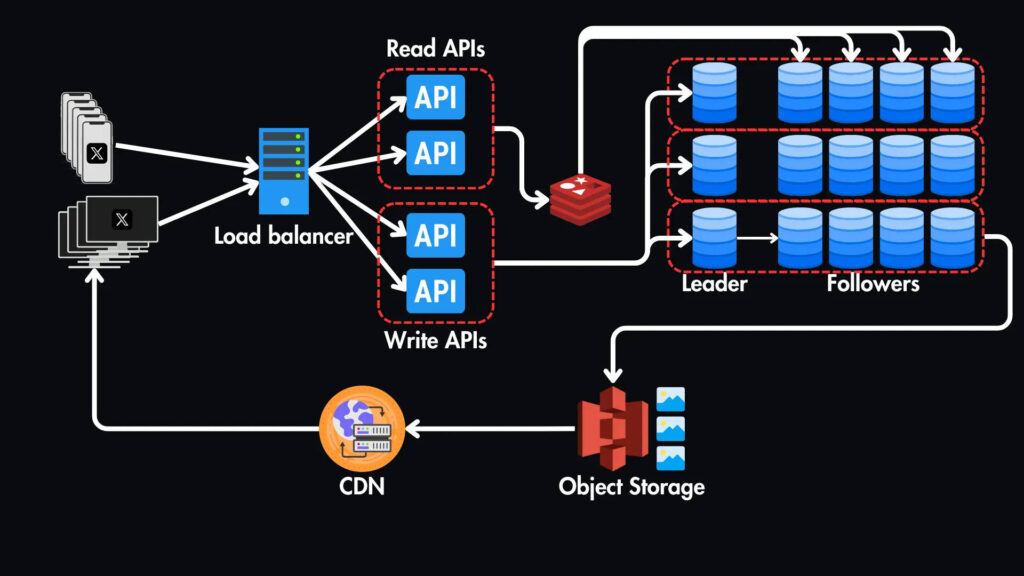
Для этого нам необходимо использовать балансировку нагрузки на слое 7 (слой приложения), которая позволяет нам принимать решения о маршрутизации на основе содержания самого запроса, например метода HTTP (GET или POST) или пути URL.
Это идеально подходит для нашего сценария, поскольку мы можем направить все запросы GET на API чтения, а все остальные запросы — на API записи.
Обработка пиковой нагрузки: очереди сообщений и разветвление
Для управления пиковым трафиком и обеспечения бесперебойной работы пользователей мы можем внедрить систему очереди сообщений. Это работает следующим образом:
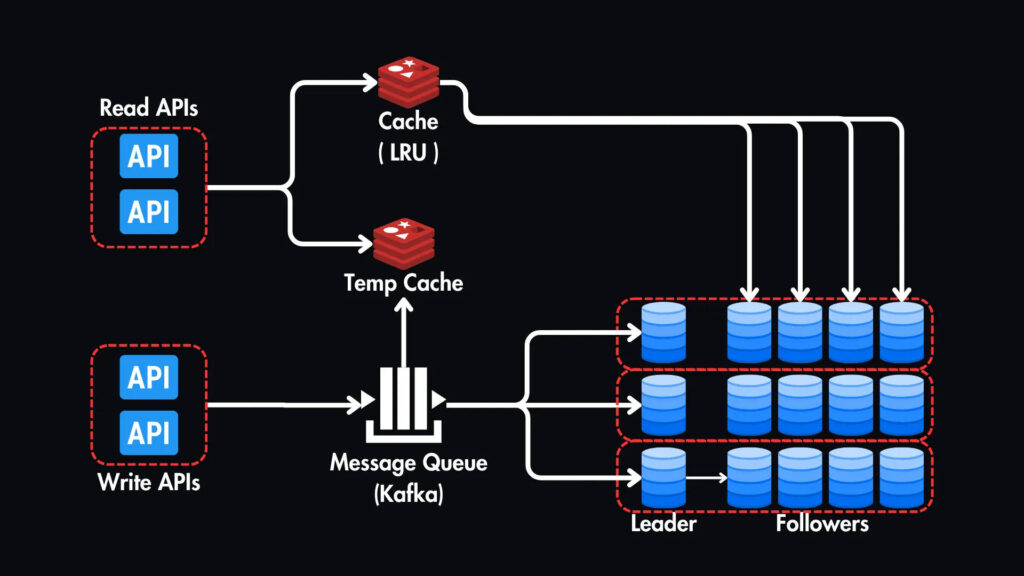
1. Публикация: когда пользователь создает твит, сервер API публикует сообщение в очереди сообщений.
2. Распространение: Затем это сообщение рассылается на несколько рабочих узлов (кластер), которые одновременно выполняют следующие задачи:
- Запись в базу данных: твит записывается в соответствующий шард базы данных.
- Обновление временного кэша: копия твита добавляется во временный кэш специально для новых твитов.
- Распространение по лентам подписчиков: твит отправляется в отдельные ленты новостей подписчиков создателя твита.
3. Чтение из кэша: пока твит записывается в базу данных, другие пользователи уже могут видеть его в своих лентах, читая из временного кэша.
4. Обновление кэша (основного): после записи твита в базу данных он также добавляется в основной кэш (LRU) для долгосрочного хранения и удаляется из временного кэша.
Итог
Вот окончательный обзор нашего высокоуровневого дизайна.
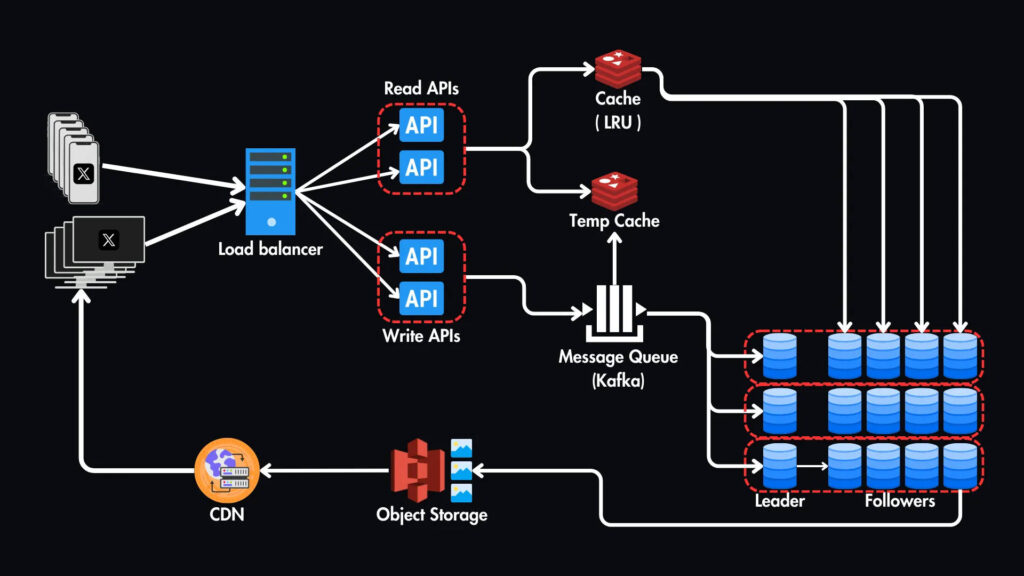
Мы рассмотрели многое, и этот обзор даст вам прочную основу, но это лишь верхушка айсберга.
Реальные системы, такие как Twitter, невероятно сложны и сталкиваются с такими проблемами, как одновременные обновления, упорядочивание твитов, разбиение на страницы и многое другое.
Если вы хотите узнать больше, вы можете прочитать официальную проектную документацию от команды Twitter .
Посмотрите анимированную видеоверсию этой статьи здесь 👇