
Оригинал: UUID Alternatives for Cloud Apps
Перевод для канала Мы ж программист
UUID уже давно стали любимым форматом идентификаторов во многих облачных и big data приложениях. Эти идентификаторы используются во многих приложениях, требующих уникальной идентификации записей, ресурсов и сущностей: базы данных, идентификаторы ресурсов, идентификаторы сессий и транзакций, хранилища объектов и т. д.
Для не-технарей: UUID = большая строка из чисел и символов с дефисами (шаблон: 8–4–4–4–12), от которой глаз дергается, такого вида 1e7cacb7-af9f-4f07–88fd-45370c25ab62
Разработчики сейчас используют альтернативные методы генерации ID, которые могут лучше соответствовать их потребностям.
Хотя UUID были и остаются широко распространенными (по-прежнему самый используемый тип ID), их большой размер и отсутствие естественной сортировки (по крайней мере, в некоторых версиях — см. ниже) могут привести к неэффективности в производительности, хранении и индексировании — в масштабе.
Кроме того, растущая популярность систем, основанных на идентификаторах с временной меткой или лексикографической сортировкой — таких как KSUID или ULID — сделала эти варианты более привлекательными.
Мы рассмотрим некоторые из доступных альтернатив, их использование, а также преимущества и недостатки. Я не буду говорить, что использовать, потому что все зависит от вашего конкретного случая. Даже для простого внутреннего POC последовательные идентификаторы могут быть достаточными (хотя обычно не рекомендуются).
Чтобы было понятно, существуют разные версии UUID.
Я не буду подробно останавливаться на каждой из них, но полезно знать, что существуют альтернативы.
- v1 (Time-based): Комбинация текущей временной метки и MAC-адреса машины, уникальна, но может раскрывать информацию об оборудовании.
- v2 (DCE Security): Аналогично версии 1, но включает информацию POSIX UID/GID, для приложений, требующих идентификации пользователей или групп.
- v3 (Name-based, MD5): Хеширует идентификатор пространства имен и имя с помощью алгоритма MD5, создавая согласованные UUID для одних и тех же входных данных.
- v4 (Random): Использует случайные числа, обеспечивая простоту и низкую вероятность дублирования.
- v5 (Name-based, SHA-1): Аналогична версии 3, но использует алгоритм хэширования SHA-1, обеспечивая более надежную хэш-функцию для генерации UUID из имен.
- v6 (Ordered Time-based): Переупорядочивание UUID версии 1 для улучшения индексации баз данных путем размещения временной метки в наиболее значимых битах, что облегчает хронологическое упорядочивание. Может подойти для некоторых случаев использования ключей баз данных, нуждающихся в упорядочивании.
- v7 (Unix Epoch Timestamp): Кодирует временную метку Unix с точностью до миллисекунды в старших 48 битах, за которыми следуют случайные данные, обеспечивая уникальность и упорядочивание по времени.
- v8 (Custom): Резервируется для пользовательских реализаций, позволяя включать в структуру UUID данные, специфичные для конкретного приложения.
В качестве примера начнем с UUIDv4, более новой версии стандарта UUID, представляющей собой 128-битное значение (16 байт), где 122 бита генерируются случайным образом, а остальные содержат информацию о версии и варианте.
Пример: 1e7cacb7-af9f-4f07–88fd-45370c25ab62
https://www.npmjs.com/package/uuid (также можно использовать crypto из node.js)
Wikipedia: Universally unique identifier
Плюсы UUIDv4:
- Высокая степень уникальности благодаря большому 122-битному случайному пространству, что делает коллизии крайне маловероятными.
- Общепризнанный стандарт, благодаря чему он широко поддерживается на многих платформах, в базах данных и языках программирования.
- Не требует координации между системами, то есть UUIDv4 может генерироваться независимо в распределенных системах без риска коллизий.
- Идеально подходит для сред, в которых множество различных машин или служб генерируют идентификаторы независимо друг от друга.
- UUID легко передавать в URL или файлах без проблем с кодировкой.
- Часть стандартной библиотеки Python или библиотека crypto в node.js также могут их создавать.
Минусы UUIDv4:
- Значительно больше, чем необходимо для некоторых случаев использования, что приводит к увеличению объема хранилища и пропускной способности.
- UUIDv4 является полностью случайным и не имеет какого-либо упорядочивания (как временные метки или последовательности). Это может быть неэффективно для баз данных, которые индексируют записи, поскольку UUIDv4 не поддерживает естественное упорядочивание. Обновление: Упорядочение можно получить с помощью UUIDv6.
- UUID — это длинные строки случайного вида, которые нелегко прочитать или запомнить человеку.
- Хотя UUIDv4 обладает высокой степенью случайности, если генератор случайных чисел слаб или предсказуем, уникальность может быть нарушена, что приведет к потенциальным коллизиям.
- В системах, где уникальность легче гарантировать (например, в пределах одной базы данных), UUIDv4 может быть излишним и неэффективным по сравнению с более простыми идентификаторами, такими как автоинкрементные целые числа.
Вот 9+ альтернатив UUID для генерации уникальных идентификаторов в программных системах, а также их плюсы и минусы:
- Автоинкрементные ID (последовательные ID)
- Snowflake ID (Twitter Snowflake)
- KSUID (K-Sortable Unique Identifier)
- ULID (Universally Unique Lexicographically Sortable Identifier)
- NanoID
- Случайный ID на основе хэша (хэширование SHA-256 или MD5)
- ObjectID (объектный ID в MongoDB)
- CUID (Collision-Resistant Unique Identifier)
- Другие (менее распространенные)
1. Автоинкрементные ID (последовательные ID)
Автоинкрементные идентификаторы — это числовые значения, которые увеличиваются на единицу каждый раз, когда добавляется новая запись, обычно используются в реляционных базах данных.
Эта альтернатива приведена в качестве примера простой реализации, с которой многие знакомятся… но, скорее всего, это не то, что вам нужно. Обычно это считается плохой практикой, если только у вас нет какого-то специального случая использования.
Минусы подчеркивают, почему серьезные производственные системы не используют последовательные идентификаторы.
Пример: 56482
Плюсы:
- Простота реализации и легкость понимания.
- Эффективны с точки зрения хранения (числовые типы данных меньше).
- Можно легко индексировать для повышения производительности баз данных.
- Подходит для небольших систем или баз данных, где порядок имеет значение и нет необходимости в глобальных уникальных идентификаторах, таких как первичные ключи в реляционных базах данных.
Минусы:
- Не подходит для распределенных систем, так как может привести к конфликтам.
- Предсказуемость, что может представлять угрозу безопасности (угадываемые идентификаторы).
- Требуется координация базы данных, чтобы избежать дубликатов в разделенных системах.
2. Snowflake ID (Twitter Snowflake)
Алгоритм распределенной генерации идентификаторов, который генерирует 64-битные уникальные ID, используя комбинацию временной метки, идентификатора машины и номера последовательности.
Пример: 5643574219214851220
Плюсы:
- Распределенный и масштабируемый, подходит для распределенных систем.
- Компонент временных меток обеспечивает приблизительное упорядочивание.
- Генерирует идентификаторы с гарантированной уникальностью в разных системах.
- Если вам нужны масштабируемые, упорядоченные по времени уникальные идентификаторы, особенно в социальных сетях или приложениях для обмена сообщениями
Минусы:
- Немного сложнее в реализации, чем простые идентификаторы.
- У идентификаторов, основанных на временных метках, может быть утечка информации о времени.
- Требуется тщательная настройка идентификаторов машин, чтобы избежать коллизий.

Wikipedia: https://en.wikipedia.org/wiki/Snowflake_ID
NPM: https://www.npmjs.com/package/snowflake-id
PyPI: https://pypi.org/project/snowflake-id/
3. KSUID (K-Sortable Unique Identifier)
KSUID — это разновидность UUID, включающая метку времени, что позволяет сортировать их по времени создания.
27-символьная строка, состоящая из временной метки и случайно сгенерированных битов, обеспечивающих k-сортируемость.
NPM: https://www.npmjs.com/package/ksuid
PyPI: https://pypi.org/project/svix-ksuid/ или https://pypi.org/project/ksuid/
Пример: 1avvTqCSFGnD5LDc4hN6GFFCAXD
Плюсы:
- K-сортировка (сортировка по времени) с сохранением глобальной уникальности.
- Компактное и эффективное представление.
- Если вам нужны уникальные, упорядоченные по времени идентификаторы с улучшенной хронологической сортировкой и уникальные идентификаторы пользовательского контента.
Минусы:
- Все же больше, чем обычные числовые ID.
- Немного сложнее в работе, чем последовательные идентификаторы.
- Может раскрывать информацию о метке времени, если вас беспокоит конфиденциальность.
4. ULID (Universally Unique Lexicographically Sortable Identifier)
Подобно KSUID, ULID — это лексикографически сортируемый формат идентификатора, сочетающий временную метку и случайные данные для обеспечения уникальности.
Буквенно-цифровая строка из 26 символов, основанная на временной метке и случайных данных, обеспечивающая лексикографическую сортировку.
NPM: https://www.npmjs.com/package/ulid
PyPI: https://pypi.org/project/python-ulid/
Пример: 22H1UECHZX3FGGSZ7A9Y9BVC1
Плюсы:
- Сортировка по времени создания.
- Более удобен для чтения человеком, чем UUID.
- Подходит для распределенных систем большого масштаба.
- Там, где требуется лексикографическая сортировка наряду с глобально уникальными идентификаторами, например в электронной коммерции или системах управления документами.
Минусы:
- Как и в случае с KSUID, временная метка раскрывается, что может не лучшим образом сказаться на конфиденциальности.
- Немного сложнее генерировать, чем UUID.
5. NanoID
NanoID — это небольшая, быстрая и безопасная альтернатива UUID, разработанная с учетом особенностей URL и настраиваемая по размеру.
Короткая, случайная, удобная для URL строка с настраиваемой длиной и алфавитом.
NPM: https://www.npmjs.com/package/nanoid
PyPI: https://pypi.org/project/nanoid/
Пример: E9SxJKL8_K5emHi2B-noZ
Плюсы:
- Компактный размер и настраиваемая длина.
- Безопасный для URL и непоследовательный, что повышает безопасность.
- Быстро генерируются и требуют меньше места для хранения, чем UUID.
- Отлично подходит для фронтенд-приложений или ситуаций, когда необходимы короткие, удобные для URL и уникальные идентификаторы, например, в публичных URL или идентификаторах сессий.
Минусы:
- Настраиваемый размер может привести к уменьшению пространства имен и потенциальным коллизиям.
- По сравнению с UUID не так широко используется в корпоративных системах.
6. Случайный ID на основе хэша (хэширование SHA-256 или MD5)
Случайно сгенерированные строки с использованием хэш-функций SHA-256 или MD5 для создания уникальных идентификаторов.
Строка фиксированной длины из 32 или 64 символов, созданная путем хэширования данных (например, комбинации временной метки и данных пользователя).
Пример:
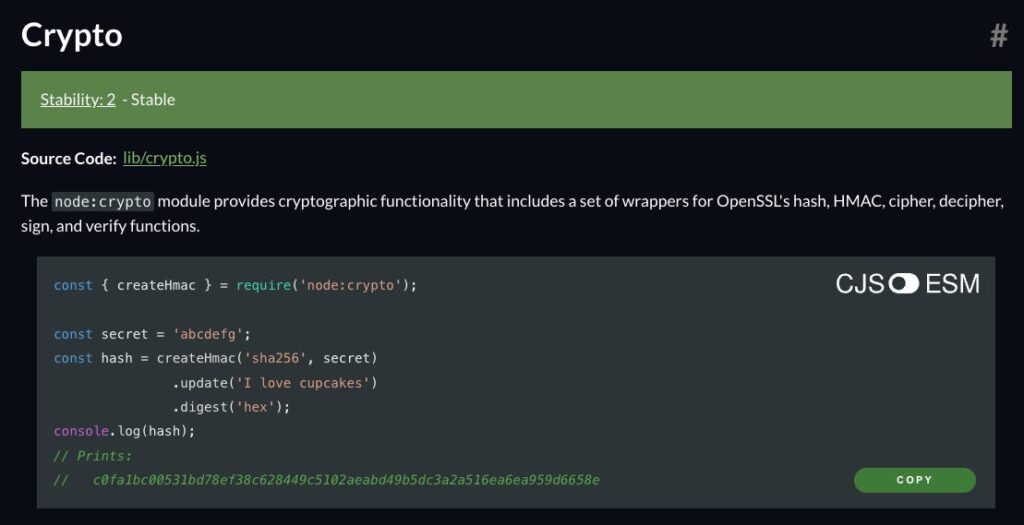
Встроено в node.js https://nodejs.org/api/crypto.html
Встроенная библиотека Python hashlib
Пример (SHA-256): 1d214892da28032151d0e36c2dc6291673603d1d61ab3dd32a11e2321d1542f2
Плюсы:
- Может генерировать очень большие уникальные пространства, практически не допуская коллизий.
- Может использовать входные данные, например данные о пользователе, для детерминированной генерации уникальных идентификаторов.
- Безопасен при использовании криптографических хэш-функций (SHA-256).
- Если вам нужна криптографическая уникальность, например, хэши файлов для дедупликации или когда идентификатор должен оставаться постоянным в разных системах.
Минусы:
- Большой объем памяти по сравнению с числовыми идентификаторами.
- Медленнее генерируются и проверяются из-за сложности вычислений.
- В зависимости от хэш-функции, может быть не полностью защищен от коллизий.
7. ObjectID (объектный ID в MongoDB)
ObjectID в MongoDB (BSON, бинарный JSON) это 12-байтный уникальный идентификатор, который включает временую метку, идентификатор машины, идентификатор процесса и счетчик.
NPM: https://www.npmjs.com/package/bson-objectid
PyPI: https://pypi.org/project/pymongo/
Пример: 102e1b71bcd16cd721434331
Плюсы:
- Обеспечивает уникальные, распределенные идентификаторы с минимальной координацией.
- Включает временную метку, позволяющую сортировать по времени создания.
- Эффективен с точки зрения хранения (12 байт, меньше, чем UUID).
- Оптимизирован для использования в базах данных NoSQL, таких как MongoDB, особенно в системах хранения документов, где требуется уникальный идентификатор с временной меткой.
Минусы:
- Раскрывает время создания, что может быть не очень удобно для обеспечения конфиденциальности.
- Привязан к MongoDB; может потребоваться некоторая адаптация для использования в других системах.
- Немного сложнее, чем базовые числовые идентификаторы.
8. CUID2 (Collision-Resistant Unique Identifier)
Cuid2 разработан для минимизации вероятности коллизий в распределенных системах, обеспечивая безопасный для URL, читаемый человеком и устойчивый к коллизиям идентификатор.
https://www.npmjs.com/package/@paralleldrive/cuid2
Пример: skbcvmzbk02217a1ad0m5qhc2
Строка, начинающаяся с «c», за которой следует временная метка в кодировке base-36 и случайность, обеспечивающая низкую вероятность столкновения.
Плюсы:
- Высокая устойчивость к коллизиям, даже в распределенных системах.
- Человекочитаемость и удобство работы с URL.
- Включает временную метку и случайный счетчик для обеспечения уникальности.
- «Горизонтально масштабируемая: Генерируйте идентификаторы на нескольких машинах без координации.» — библиотека npm по ссылке выше
- «Совместимость с оффлайном: Генерируйте идентификаторы без подключения к сети.» — библиотека npm по ссылке выше
- Для создания надежного уникального идентификатора с низким риском коллизий, например, в распределенных базах данных или микросервисах.
Минусы:
- Крупнее, чем более простые форматы идентификаторов, такие как NanoID или Snowflake.
- Может раскрывать некоторые детали (например, временные метки и информацию о машине).
- Более сложный процесс генерации по сравнению с последовательными или числовыми идентификаторами.
9. Другие (менее распространенные)
Вот некоторые другие, которые я обнаружил в ходе своих исследований, но они менее распространены. Если вы не нашли лучшего идентификатора для вашего случая использования, возможно, стоит обратить внимание на эти варианты.
Flake ID. Включает в себя временную метку, идентификатор машины и порядковый номер. Если вам нужны уникальные, упорядоченные по времени идентификаторы для упрощения сортировки и отладки.
Пример: 304857642123456
ID, основанные на времени. Часто это временная метка Unix, скомбинированная со случайными битами или другими уникальными данными. Важен хронологический порядок, например, при ведении журнала или отслеживании событий.
Пример: 16972283871234567890 (объединяет временную метку 1697228387 со случайным суффиксом).
Последовательные GUID (SQL Server). GUID, оптимизированный для индексирования, часто начинающийся с сегмента, упорядоченного по времени. В тех случаях, когда GUID необходимы, но для повышения производительности базы данных требуется упорядоченное индексирование.
Пример: 6E4F6A80-4F64-11EE-B4FA-0242AC120002
ShortID. Генерирует компактную, уникальную буквенно-цифровую строку, часто используемую в URL. Сокращение URL или удобные для пользователя идентификаторы в публичных URL.
Пример: 2K5czP8
ZUID (Zero-width Unique Identifier). Использует символы нулевой ширины (например, пробелы нулевой ширины), которые невидимы, но могут быть разобраны на предмет уникальности. Если вам нужны невидимые идентификаторы для отслеживания или метаданных, не влияющие на визуальное оформление.
Пример: Внутри сайта может выглядеть как \u200B\u200C\u200D
Вот и все! Мы подробно рассказали об альтернативах UUID, и я надеюсь, что это даст вам дополнительную информацию о малоизвестной (для некоторых) теме, которая поможет вам создавать лучшие приложения.