
Оригинал: 20 Most Important AI Concepts Explained in Just 20 Minute
Перевод для канала Мы ж программист
Базовые понятия
1. Нейросети
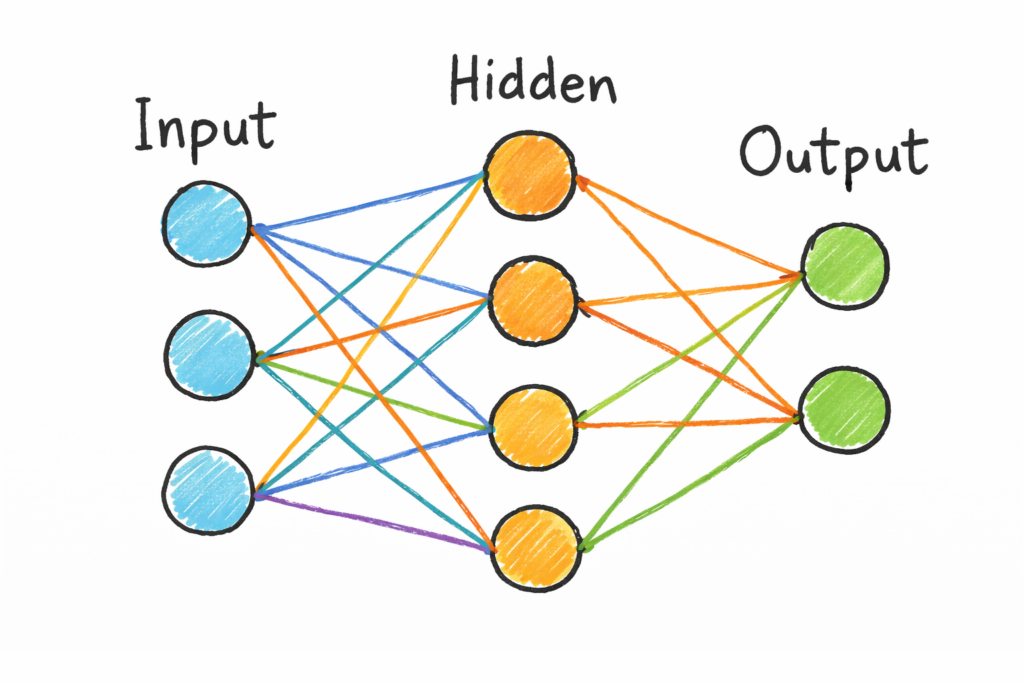
По сути, нейронная сеть — это просто система связанных между собой слоёв, состоящая из небольших элементов, называемых нейронами.
Представьте себе это как конвейер.
Данные поступают через входной слой, проходят через несколько скрытых слоёв и, наконец, выходят в виде прогноза через выходной слой.
Но что на самом деле происходит внутри? Проще всего это понять, представив себе пошаговое уточнение.
Один и тот же входной сигнал обрабатывается снова и снова, и с каждым слоем модель понимает его чуть лучше.
Например, в модели обработки изображений:
- Первые слои могут обнаруживать простые элементы, такие как края или текстуры;
- Средние слои начинают распознавать формы или узоры;
- А более глубокие слои могут идентифицировать реальные объекты.
Это похоже на переход пиксели → фигуры → смысл.
А теперь самое важное… Каждая связь между этими нейронами имеет так называемый вес (weight).
Можно представить себе веса как крошечные «показатели важности», которые определяют, насколько один нейрон должен влиять на другой.
А что такое обучение нейронной сети?
По сути, это процесс постоянной корректировки этих весов, пока модель не начнёт давать точные результаты.
И вот тут всё становится просто невероятным. Современные модели ИИ, особенно крупные языковые модели, имеют не просто несколько весов. Их миллиарды.
И все они работают вместе, чтобы превратить необработанные входные данные в нечто, что действительно имеет смысл.
2. Трансферное обучение
Обучение нейронной сети с нуля звучит круто… пока не осознаешь, насколько это на самом деле дорого.
Для этого требуются огромные объёмы данных, значительные вычислительные мощности и много времени.
Именно здесь на помощь приходит трансферное обучение, и, честно говоря, оно меняет всё.
Вместо того чтобы начинать с нуля, вы берёте модель, уже обученную для решения широкой задачи, и адаптируете её для чего-то более конкретного.
Таким образом, вы не создаёте всё с нуля… вы строите на основе того, что уже работает.
Проще всего это понять на примере повторного использования навыков.
Представьте, что вы уже умеете ездить на велосипеде. Теперь научиться ездить на мотоцикле становится гораздо проще, верно? Ведь вы не начинаете с нуля, а просто адаптируете то, что уже знаете.
Переносное обучение работает точно так же.
Предварительно обученная модель уже усвоила общие закономерности в данных, поэтому при ее дообучении под конкретный сценарий использования она обучается гораздо быстрее и с гораздо меньшими затратами.
И вот что важно… Именно так сегодня работает большинство современных систем ИИ.
Крупные компании один раз обучают огромные базовые модели, а затем разработчики, такие как мы, адаптируют их для конкретных задач.
Именно поэтому вы можете создавать мощные приложения на базе ИИ, не нуждаясь в миллиардах точек данных или безумных вычислительных мощностях.
Стек трансформера
3. Токенизация
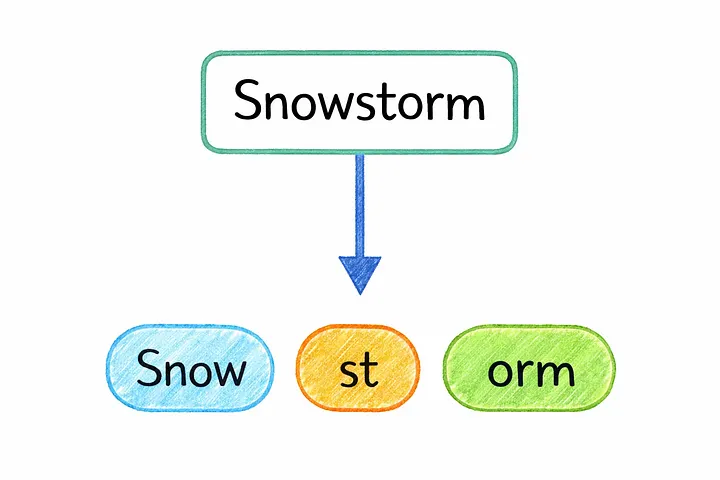
Прежде чем модель сможет понять какой-либо текст, ей необходимо разбить его на более мелкие части. Этот процесс называется токенизацией.
Вместо того чтобы читать предложения так, как это делаем мы, модель работает с крошечными единицами, называемыми токенами. Эти токены действуют как внутренний «алфавит» модели для языка.
Однако токен не всегда представляет собой целое слово.
Иногда это целое слово, а иногда — лишь его часть. Например, слово «playing» может быть разбито на более мелкие части, такие как «play» и «ing». С другой стороны, короткое и распространённое слово, такое как «dog», обычно остаётся без изменений.
Пример:
Вы можете попробовать это самостоятельно здесь.
Сначала это может показаться немного странным, но на то есть веская причина.
Язык невероятно хаотичен и постоянно развивается. Постоянно появляются новые слова, люди допускают орфографические ошибки, смешивают языки или придумывают собственные варианты. Если бы модель пыталась запомнить каждое возможное слово, её словарный запас стал бы непомерно большим.
Токенизация решает эту проблему, используя фиксированный набор строительных блоков. Вместо того чтобы запоминать каждое слово, модель изучает общие шаблоны и повторно используемые фрагменты. Поэтому даже если она сталкивается со словом, которое никогда раньше не видела, она всё равно может его понять, разбив его на знакомые части.
Вот почему ИИ на самом деле не читает текст так, как это делают люди.
Он читает токены и на их основе шаг за шагом выстраивает смысл.
4. Эмбеддинги
Как только текст разбит на токены, следующий шаг — превращение этих токенов во что-то, с чем модель может реально работать.. Здесь и появляются эмбеддинги.
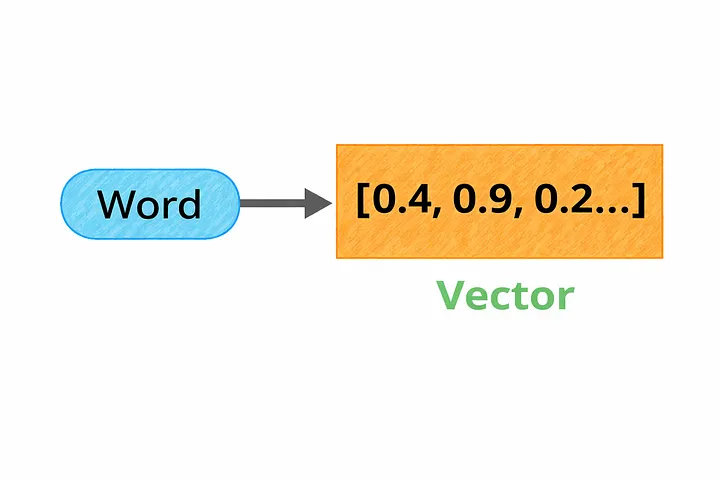
Каждый токен преобразуется в вектор — по сути, список чисел, отражающий его значение. Вместо того чтобы работать напрямую со словами, модель оперирует этими числовыми представлениями.
Полезно представить себе это как своего рода карту.
Каждому слову присваивается положение в многомерном пространстве. Похожие слова оказываются рядом друг с другом, а сильно отличающиеся — на большом расстоянии. Например, слова «врач» и «медсестра» будут находиться рядом, а «врач» и «гора» — гораздо дальше друг от друга.
Несмотря на то что это пространство имеет сотни или тысячи измерений, оно по-прежнему отражает значимые взаимосвязи. Различия между некоторыми словами подчиняются определённым закономерностям. Например, связь между словами «актёр» и «актриса» схожа со связью между словами «принц» и «принцесса».
Интересно то, что модель не понимает язык так, как мы. Она не мыслит определениями или правилами.
Вместо этого она понимает значение через расстояние и направление, организуя слова в пространстве, где связи приобретают геометрическую форму.
5. Внимание
Вот тут всё становится уже действительно интересно.
Значение слова не является фиксированным — оно зависит от контекста.
Возьмём, к примеру, такое простое слово, как «apple». В одном предложении оно может означать фрукт. В другом — компанию.
Как же модель определяет правильное значение?
Одних только эмбеддингов недостаточно, поскольку они исходят из фиксированного представления каждого токена. Они не в полной мере отражают, как значение меняется в зависимости от окружающих слов.
Именно здесь на помощь приходит механизм внимания (attention).
Механизм внимания позволяет каждому слову «взглянуть» на все остальные слова в предложении и определить, что действительно важно. Вместо того чтобы рассматривать все слова одинаково, модель учится сосредотачиваться на наиболее релевантных из них.
Так, если предложение звучит как «Она купила акции Apple», модель уделит больше внимания таким словам, как «акции» и «купила», что поможет ей понять, что «Apple» — это компания, а не фрукт.
Сила этого подхода заключается в том, что модель больше не анализирует текст слово за словом.
Она рассматривает предложение целиком и динамически определяет, на чем следует сосредоточить внимание.
Именно эта концепция «внимания» стала ключом к развитию современного ИИ.
Раньше модели обрабатывали текст пошагово, слева направо, часто упуская связи между элементами, расположенными на большом расстоянии друг от друга. Механизм внимания изменил эту ситуацию, позволив модели увидеть полную картину и понять, как всё взаимосвязано.
6. Трансформер
Все эти кусочки, о которых мы говорили выше — токены, эмбеддинги, анимание — наконец собирются вместе в одно целое.
Это место называется трансформер.
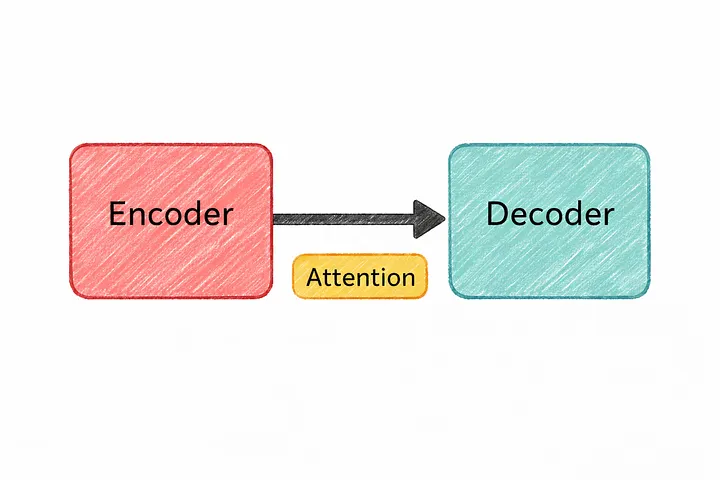
Именно эта архитектура лежит в основе практически всех современных систем искусственного интеллекта.
Трансформер был представлен в статье 2017 года под названием «Attention Is All You Need». Идея оказалась удивительно простой: вместо обработки текста по одному слову за раз сделать механизм внимания основным и позволить модели рассматривать весь текст сразу.
Этот подход изменил всё.
Трансформер построен путем наложения нескольких слоёв механизма внимания на простые блоки обработки. По мере прохождения информации через эти слои она шаг за шагом уточняется.
На ранних слоях модель сначала понимает базовую структуру — такие вещи, как грамматика и синтаксические конструкции.
По мере продвижения вглубь она начинает улавливать связи между словами и идеями. А на более поздних слоях она способна обрабатывать более сложные логические выводы и взаимосвязи.
Это не магия, а просто постоянное совершенствование.
Одно из главных преимуществ трансформеров заключается в том, как они обрабатывают данные.
Старые модели были вынуждены считывать текст последовательно, по одному слову за раз. Из-за этого они работали медленно и могли обрабатывать лишь ограниченный объем контекста.
У трансформеров этой проблемы нет. Они обрабатывают все токены параллельно, что делает их гораздо быстрее и позволяет масштабировать их до огромных размеров с помощью современного оборудования, такого как графические процессоры (GPU).
Именно поэтому такие модели, как GPT, Claude, Gemini и Llama, все построены на этой архитектуре.
Если посмотреть на процесс в целом, весь конвейер выглядит следующим образом:
- Текст разбивается на токены.
- Токены превращаются в векторы.
- Слои трансформера используют внимание, чтобы понять, как всё это соединяется.
Именно этот простой алгоритм лежит в основе большинства систем искусственного интеллекта, которыми вы пользуетесь сегодня.
Большие языковые модели
7. LLM (Large Language Model)
А теперь давайте свяжем всё это с тем, с чем сегодня на самом деле взаимодействует большинство людей — с большими языковыми моделями, или LLM.
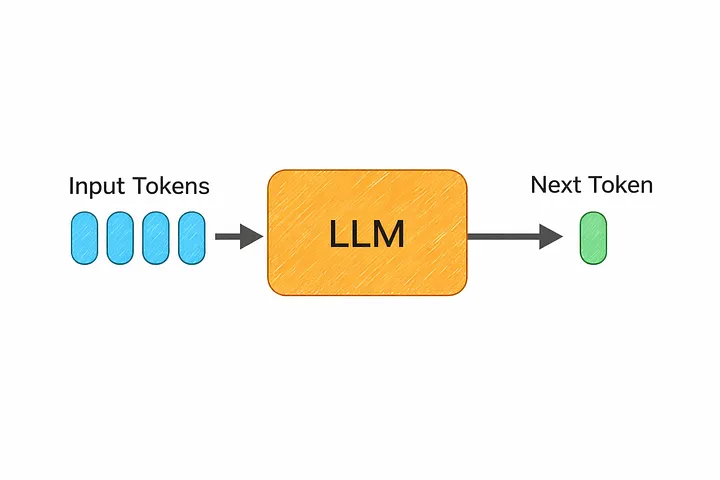
В общем и целом, LLM — это просто трансформер, обученный на огромном объеме текста. Речь идет о данных из книг, веб-сайтов, кода и т. д., а объем данных зачастую составляет сотни миллиардов или даже триллионы токенов.
А какова цель обучения? На удивление простая.
Модель учится, пытаясь предсказать следующий токен. Вот и всё.
Звучит почти слишком просто, чтобы быть эффективным. Но когда этот процесс повторяется на триллионах примеров, происходит нечто интересное.
Модель начинает улавливать языковые закономерности. Она учится понимать, как строят предложения, как связываются идеи и даже как протекает ход мысли. Со временем это начинает очень напоминать понимание, хотя на самом деле это всего лишь изучение закономерностей в огромных масштабах.
Именно поэтому эти модели способны выполнять такие задачи, как: написание кода, ответы на вопросы, перевод с одного языка на другой или объяснение сложных тем, даже если они никогда явно не обучались именно этим задачам.
Термин «большая» в названии «большая языковая модель» относится к количеству параметров.
Это внутренние значения, которые модель усваивает в процессе обучения, и современные модели имеют сотни миллиардов таких параметров.
Обучение в таких масштабах обходится недешево. Для этого требуются огромные вычислительные ресурсы, и зачастую это стоит миллионы долларов.
Но в результате получается система, способная обобщать широкий спектр задач и генерировать удивительно полезные результаты.
Поэтому, когда вы используете такие инструменты, как ChatGPT, Claude или Gemini… вы на самом деле взаимодействуете с моделью, которая научилась языку, выполняя одно простое действие
снова и снова — предсказывая, что будет дальше.
8. Контекстное окно
Каждая ИИ-модель имеет предел, как много она может «запомнить» за раз. Этот предел называется контекстым окном.
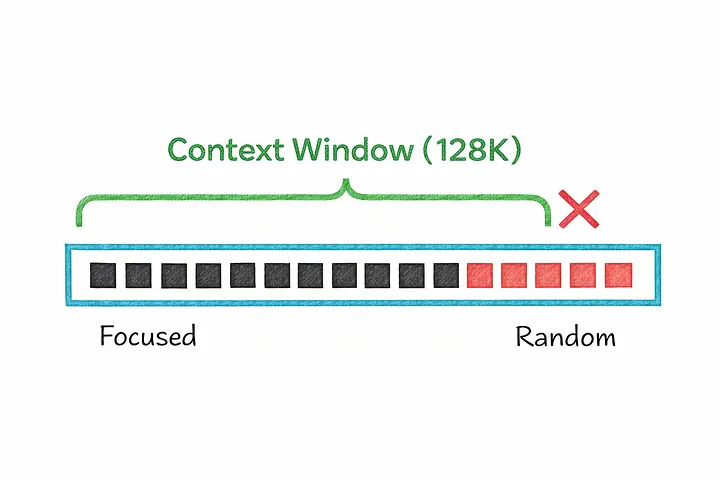
Этот показатель отражает максимальное количество токенов, которое модель может обработать за одно взаимодействие, включая как ваш текст, так и текст, сгенерированный моделью в ответ. Проще говоря, это своего рода краткосрочная рабочая память модели.
В ранних моделях объём этой памяти был довольно небольшим.
Например, ранние версии GPT могли обрабатывать одновременно лишь несколько тысяч токенов. Это означало, что в длинных диалогах быстро терялись предыдущие детали, а объёмные документы приходилось сокращать или разбивать на части.
Но ситуация значительно изменилась.
Современные модели способны обрабатывать гораздо более обширные контексты. Некоторые из них могут одновременно обрабатывать целые книги, длинные диалоги или большие фрагменты кода. Это делает их гораздо более полезными для реальных задач, где контекст действительно имеет значение.
Но есть одна загвоздка.
Более широкое контекстное окно имеет свои недостатки.
Оно требует больше памяти, больших вычислительных ресурсов и зачастую приводит к замедлению отклика. Поэтому, хотя в теории «больше — значит лучше», на практике это делает систему более тяжелой и дорогой в эксплуатации.
И даже при использовании больших контекстных окон существует ещё одно незаметное ограничение.
Модели не обрабатывают все части входных данных одинаково. Они, как правило, уделяют больше внимания началу и концу, в то время как информация, спрятанная в середине, иногда может остаться незамеченной. Эту проблему часто называют «потерянной серединой».
Поэтому, хотя контекстные окна становятся всё больше и лучше… они всё ещё не идеальны.
И понимание этого помогает объяснить, почему иногда модель «забывает» вещи, о которых вы явно упоминали ранее.
9. Температура
Когда языковая модель генерирует текст, она не просто напрямую выбирает следующее слово.
За кулисами она вычисляет вероятности для каждого возможного следующего токена, а затем решает, какой из них выбрать.
Именно здесь и играет роль параметр температура.
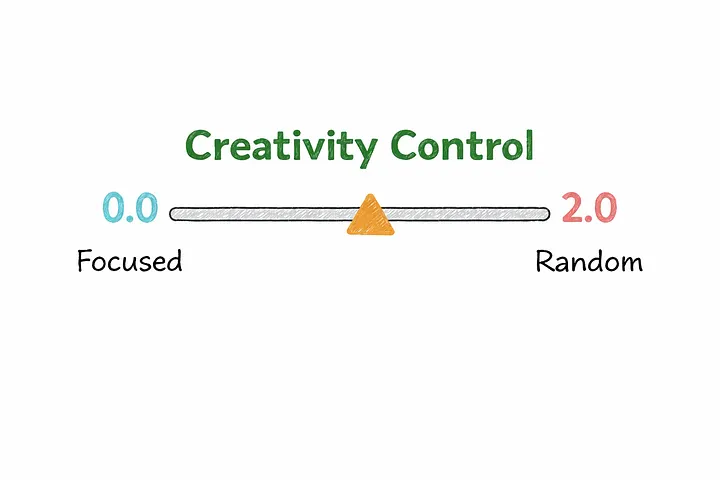
Температура определяет, насколько «строгим» или «креативным» будет этот выбор.
При очень низком значении температуры модель действует осторожно.
Она почти всегда выбирает наиболее вероятный следующий токен, что делает результат более предсказуемым, целенаправленным и последовательным. Именно поэтому низкое значение температуры хорошо подходит для таких задач, как написание кода, составление резюме или любых других задач, где точность важнее креативности.
По мере увеличения значения температуры модель становится более гибкой.
Вместо того чтобы всегда выбирать лучший вариант, она начинает исследовать другие возможности, основываясь на их вероятностях. Это добавляет разнообразия и делает результат более естественным или творческим, что полезно, например, для генерации идей или написания различных вариаций одного и того же контента.
Если повысить температуру ещё выше, результат станет непредсказуемым.
Модель может генерировать более неожиданные или творческие ответы, но при этом она может быстро утратить связность, особенно в длинных текстах. В этот момент речь идет уже не столько о точности, сколько об экспериментах.
Таким образом, на практике температура — это просто способ управления поведением модели.
Более низкие значения делают её более точной и надёжной.
Более высокие значения делают её более креативной и разнообразной.
А выбор правильного баланса полностью зависит от того, чего вы пытаетесь добиться.
10. Галлюцинации
Это одна из первых вещей, которые вы замечаете, когда начинаете серьезно работать с ИИ.
Иногда модель дает ответ, который звучит совершенно уверенно… но оказывается неправильным.
Это называется галлюцинацией.
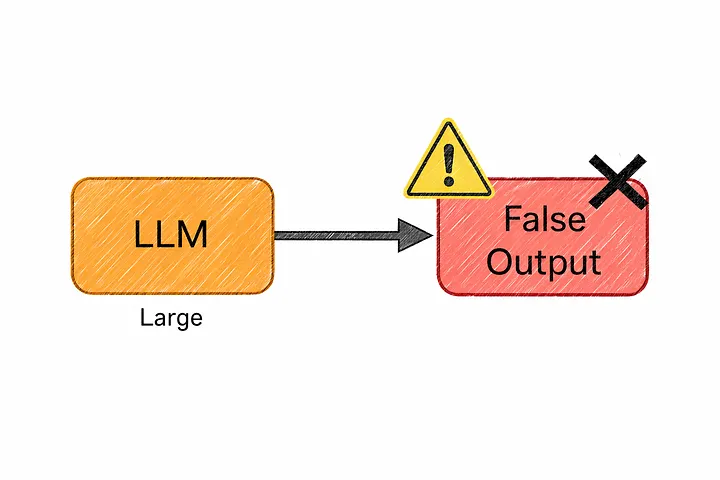
Она может с полной уверенностью сослаться на несуществующее исследование, предложить API, которого никогда не создавали, или представить выдуманный факт так, будто это общеизвестная информация. И самое коварное в том, что это звучит правдоподобно.
Почему же так происходит?
Потому что по сути своей языковая модель не стремится говорить правду. Она пытается сгенерировать наиболее вероятный следующий фрагмент текста.
Она выучила закономерности на основе огромных объемов данных, и её задача — продолжать эти закономерности так, чтобы текст звучал естественно и связно. Но она на самом деле не проверяет, верно ли то, что она говорит.
Поэтому, если ложное утверждение выглядит как то, что должно следовать дальше, модель с полной уверенностью сгенерирует его.
И именно это делает галлюцинации такой серьёзной проблемой при использовании в реальных условиях. Нельзя просто слепо доверять результатам, особенно когда речь идёт о фактах, коде или важных решениях.
Именно поэтому многие современные системы пытаются смягчить эту проблему, привязывая модель к реальным данным — например, сопоставляя её с достоверными документами или требуя от неё ссылок на источники, когда это возможно.
В конечном итоге модель невероятно хорошо умеет звучать убедительно. Но ей по-прежнему нужен человек (вы), чтобы проверить, действительно ли это верно.
Обучение и оптимизация
11. Тонкая настройка
Тонкая настройка — это то, что происходит после того, как модель уже освоила основы.
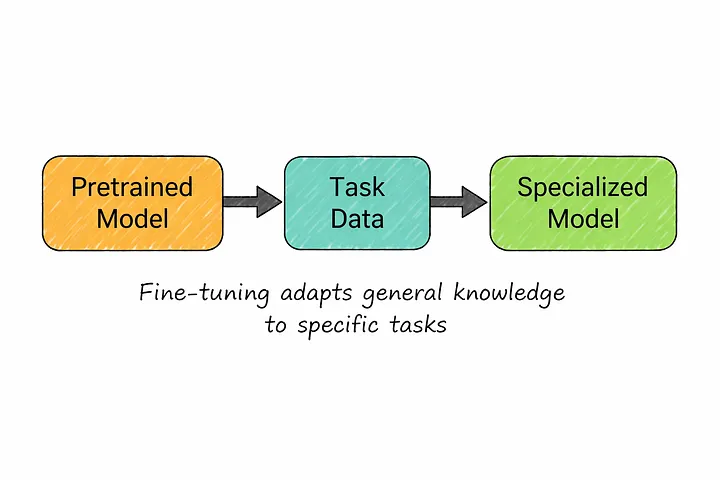
Вместо того чтобы обучать модель с нуля, вы берете предварительно обученную модель и продолжаете ее обучение на меньшем, более узконаправленном наборе данных. Модель уже понимает язык в целом, поэтому вы не обучаете ее с нуля, а просто направляете в конкретном направлении.
Представьте себе это как специализацию.
Общая модель может хорошо отвечать на всевозможные вопросы, но если вы хотите, чтобы она действительно хорошо работала в конкретной области, вы можете настроить её с помощью более целенаправленных данных.
Например, если вам нужна модель, понимающая юридические документы, вы можете дополнительно обучить её на контрактах, кратких изложениях судебных дел и юридических разъяснениях. Со временем она начнёт отвечать так, как лучше подходит для этой области.
Но это сопряжено с определёнными затратами.
Тонкая настройка обычно предполагает обновление значительной части внутренних параметров модели. А поскольку эти модели огромны, для этого процесса требуется мощная инфраструктура.
Вам понадобится достаточно памяти, чтобы загрузить всю модель вместе со всеми дополнительными данными, необходимыми во время обучения. Для очень больших моделей это часто означает использование нескольких высокопроизводительных графических процессоров и значительных вычислительных ресурсов.
Таким образом, хотя точная настройка и является мощным инструментом, она не всегда проста в реализации и не всегда легко настраивается.
Она дает вам возможность контроля и настройки под свои нужды, но за это приходится платить сложностью и затратами.
12. RLHF (Обучение с подкреплением на основе обратной связи от человека)
До этого момента всё, о чём мы говорили, объясняет, как модель обучается языку. Но это не объясняет одну важную вещь…
Почему современные модели ИИ кажутся такими полезными, вежливыми и способными вести беседу?
Именно здесь на сцену выходит RLHF (Reinforcement Learning from Human Feedback).
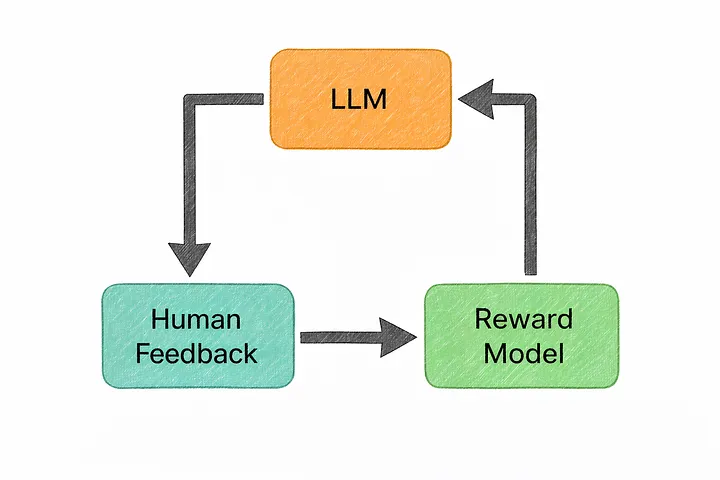
По сути, именно RLHF превращает модель, которая «просто предсказывает следующий токен», в систему, которая соответствует человеческим ожиданиям.
Без него модель по-прежнему генерировала бы беглый текст, но он не обязательно был бы полезным, безопасным или даже уместным. Она просто продолжала бы следовать тому шаблону, который кажется наиболее вероятным, независимо от того, помогает ли это вам на самом деле.
Так как же RLHF решает эту проблему?
Он вводит человеческое суждение в процесс обучения.
Вместо того чтобы полагаться исключительно на исходные данные, модель ориентируется на то, что на самом деле предпочитают люди. На заданный запрос модель генерирует несколько возможных ответов, а люди сравнивают их и решают, какие из них более полезны, понятны или безопасны.
Со временем модель учится отдавать предпочтение тем ответам, которые люди выбирают наиболее часто.
Интересно то, что модель не запоминает эти ответы напрямую. Она учится понимать суть предпочтений.
Она начинает понимать такие вещи, как:
— как выглядит хороший ответ,
— как правильно следовать инструкциям,
— и когда следует избегать вредных или вводящих в заблуждение ответов.
Именно поэтому современные чат-боты воспринимаются совсем иначе, чем старые системы. Они не просто говорят бегло — создается ощущение, что они действительно пытаются вам помочь.
Без RLHF (или аналогичных методов согласования) модель по-прежнему была бы мощной… но она была бы гораздо менее надёжной, менее безопасной и гораздо сложнее в использовании в реальных приложениях.
13. LoRA (Low-Rank Adaptation)
Мы только что говорили о тонкой настройке и о том, насколько она эффективна. Но есть одна проблема.
Тонкая настройка огромной модели подразумевает обновление миллиардов параметров, что быстро становится дорогостоящим и сложным для управления. Не у всех есть доступ к такой инфраструктуре.
Именно здесь на помощь приходит LoRA.
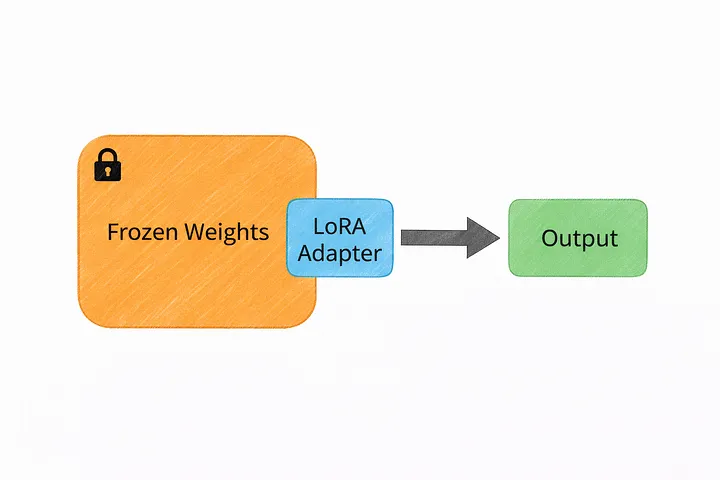
Вместо того чтобы модифицировать всю модель целиком, LoRA использует гораздо более «легкий» подход.
Он оставляет исходную модель «замороженной» и добавляет поверх неё небольшие обучаемые компоненты. Эти дополнительные элементы крошечны по сравнению с полной моделью — зачастую они составляют лишь долю процента от общего числа параметров.
Таким образом, вместо того чтобы переписывать всю систему заново, вы просто вносите небольшие корректировки там, где это необходимо.
Идея, лежащая в основе этого подхода, удивительно гениальна.
При тонкой настройке модели большинство изменений на самом деле не требует полномасштабных обновлений. Их можно аппроксимировать с помощью гораздо меньших преобразований. LoRA использует это в своих интересах и фиксирует эти изменения в компактной форме.
Почему это важно?
Потому что это значительно упрощает процесс тонкой настройки.
То, что раньше требовало использования нескольких высокопроизводительных графических процессоров, теперь зачастую можно выполнить на одном компьютере. И вместо того, чтобы сохранять несколько полных версий модели, можно хранить различные адаптеры LoRA и переключаться между ними в зависимости от задачи.
Проще говоря, LoRA дает вам все преимущества тонкой настройки… без значительных затрат, которые обычно с этим связаны.
14. Квантизация
С увеличением размера модели их запуск становится сложнее. Они требуют больше памяти, больше процессоров, мощнее оборудование.
Здесь и появляется квантизация (или квантование).
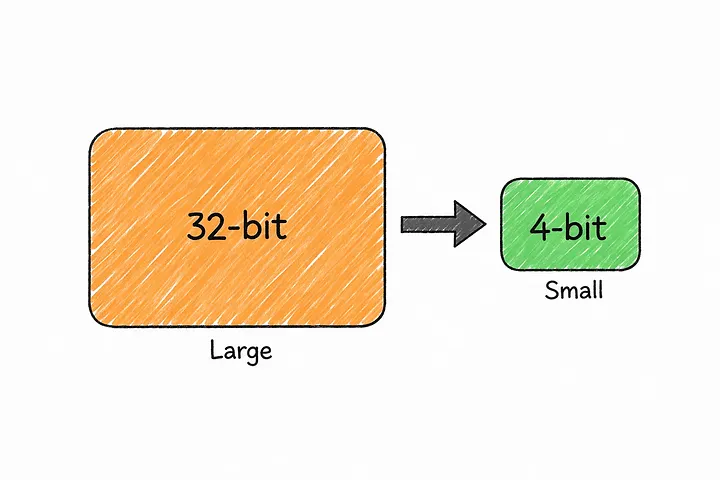
Квантизация — это, по сути, способ уменьшить размер моделей и снизить затраты на их запуск за счет более эффективного хранения весов.
В модели с полной точностью каждый вес хранится с использованием большого количества битов. Квантизация позволяет сократить этот размер, порой значительно, что означает, что вся модель занимает гораздо меньше памяти.
Идея проста: использовать меньшую точность, но сохранить большую часть полезной информации.
Когда вы уменьшаете размер каждого веса, эффект быстро накапливается.
Модель, которая обычно требовала бы огромного объема памяти, может внезапно стать достаточно компактной, чтобы работать на более доступном оборудовании. И, что удивительно, снижение качества зачастую оказывается гораздо меньшим, чем можно было бы ожидать, особенно при умеренных уровнях квантования.
Это одна из ключевых причин, по которой крупные модели становятся всё более практичными.
Когда вы видите, как люди запускают мощные модели на настольном графическом процессоре или даже на ноутбуке, они, как правило, используют не полную версию. Они используют квантованную версию, сжатую с учётом реальных ограничений.
Проще говоря, именно квантование помогает вывести крупные модели ИИ из огромных центров обработки данных… и перенести их на повседневные устройства.
Запросы и размышления
15. Разработка запросов (промптов)
Если вы хотя бы немного пользовались ИИ, то, вероятно, уже заметили… То, как вы формулируете запрос, имеет огромное значение.
Именно в этом и заключается суть разработки промптов.
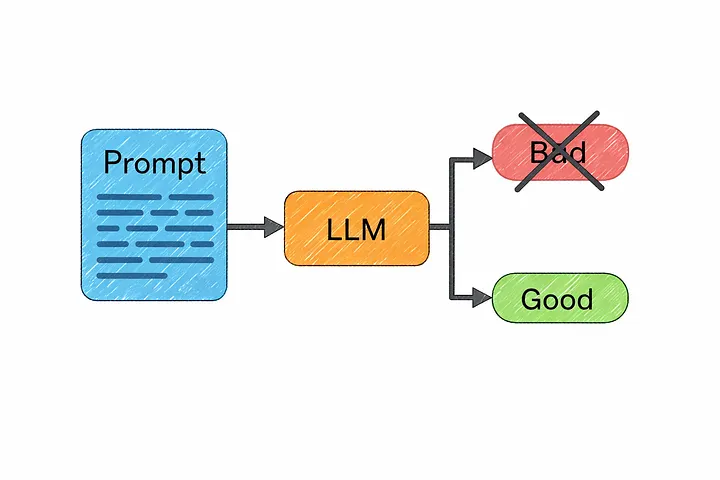
Это процесс корректировки входных данных, чтобы модель выдавала более качественные и полезные результаты.
Один и тот же вопрос, заданный двумя разными способами, может привести к совершенно разным результатам.
Если вы скажете что-то вроде «объясни, что такое API», модель, как правило, даст вам общий, поверхностный ответ. Но если вы спросите: «Объясни, как REST-API обрабатывают аутентификацию, приведя реальный пример», — вы дадите ей конкретное направление, и результат сразу станет более целенаправленным и практичным.
Хороший запрос отличается не сложностью, а ясностью.
Когда вы чётко определяете, чего хотите, у модели появляется гораздо больше шансов дать вам именно это. Иногда это означает задание роли, например, просьбу ответить как опытный инженер. В других случаях это означает приведение примеров, разбиение задачи на этапы или просто конкретизацию формата и тона.
Со временем вы осознаёте одну важную вещь. Инженерия подсказок — это не просто трюк или обходной путь. Это основной способ вашего общения с моделью. И разница, которую это вносит, огромна.
Расплывчатый промпт даёт общий результат. Хорошо сформулированный промпт может дать вам что-то структурированное, точное и действительно применимое на практике.
16. Цепочка рассуждений (CoT)
Иногда модель дает неверный ответ не потому, что ей ничего не известно, а потому, что она слишком быстро приходит к ответу.
Именно здесь и приходит на помощь цепочка рассуждений (chain of thought).
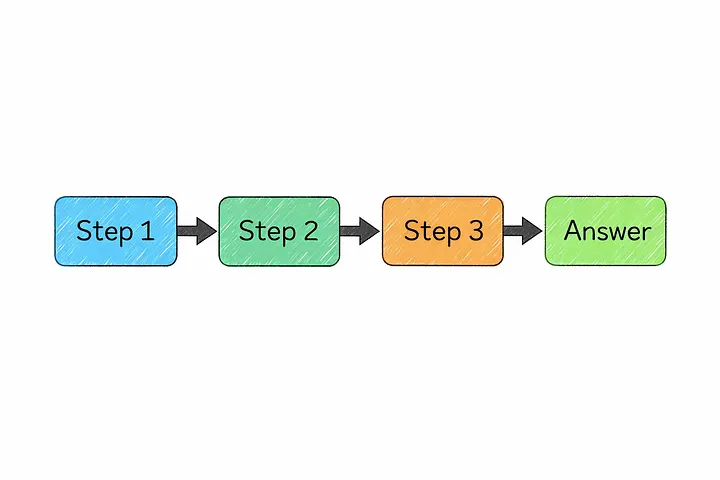
Это подход с подсказками, при котором модель решает задачу промежуточными шагами, а не спешит сразу к конечному результату. Как правило, это очень помогает при решении задач, связанных с логикой, математикой или чем-либо, что требует нескольких этапов рассуждений.
Проще говоря: если вы просите только конечный ответ, модель может слишком полагаться на сопоставление шаблонов. Но если побудить её решать задачу более тщательно, у неё появляется больше шансов прийти к правильному решению.
Например, если попросить модель сразу решить задачу на умножение, она иногда может дать неверный ответ. Но если сначала разбить задачу на более мелкие части, а затем объединить их, ответ станет гораздо более достоверным.
Именно поэтому цепочку мысли часто описывают как предоставление модели своего рода рабочего пространства.
Вместо того чтобы требовать мгновенного ответа, вы позволяете ей обрабатывать задачу небольшими шагами. И для многих задач, требующих интенсивного логического мышления, это небольшое изменение может иметь огромное значение.
Проще говоря, лучшие результаты часто достигаются, когда модели дают возможность логически проработать задачу… вместо того чтобы просить её сразу перейти к выводу.
Построение ИИ-систем
17. RAG (Retrieval-Augmented Generation)
Помните про проблему галлюцинаций, о которой говорили выше? RAG — один из наиболее практичных способов работать с этим.
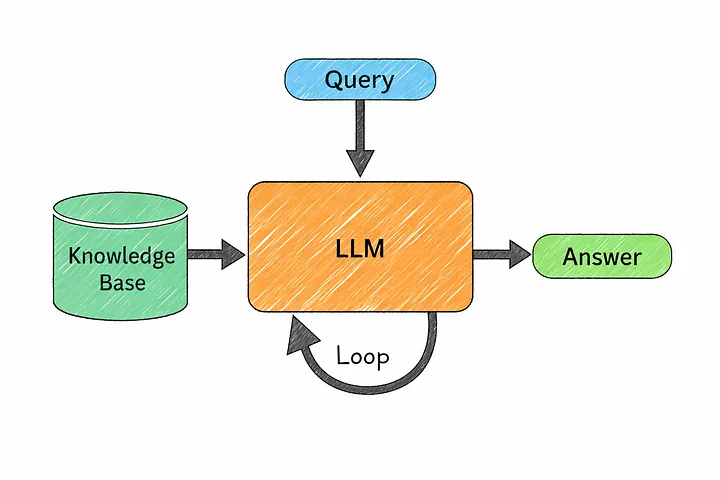
Идея проста.
Вместо того чтобы полагаться исключительно на то, что модель уже знает, вы предоставляете ей доступ к реальной, актуальной информации именно в тот момент, когда она формулирует ответ.
Перед формированием ответа система сначала ищет полезные документы в базе знаний. Затем эти документы передаются в модель в качестве контекста, и модель использует их для формирования более обоснованного ответа.
Представьте себе это так.
Вместо того чтобы отвечать по памяти, модели разрешается сначала найти нужную информацию.
Например, представьте, что вы разрабатываете помощника службы поддержки. Когда кто-то задает вопрос о ценах или правилах, система не пытается угадать ответ. Сначала она извлекает самую свежую информацию из ваших внутренних документов, а затем модель объясняет её понятно и естественно.
Сила этого подхода заключается в разделении ролей.
Модель сосредоточена на понимании вопроса и объяснении ответа. База знаний предоставляет фактические данные.
И в этом заключается большое преимущество.
Если ваша информация изменится, вам не нужно переобучать модель. Достаточно просто обновить документы, и система сразу же начнёт использовать новые данные.
Проще говоря, RAG превращает модель из чего-то, что просто запоминает… в нечто, что умеет читать, проверять и отвечать с учётом реального контекста.
И именно это делает её гораздо более надёжной для использования в реальных условиях.
18. Векторная база данных
Итак, если суть RAG заключается в поиске нужной информации… то как же система на самом деле её находит?
Именно здесь на помощь приходят векторные базы данных.
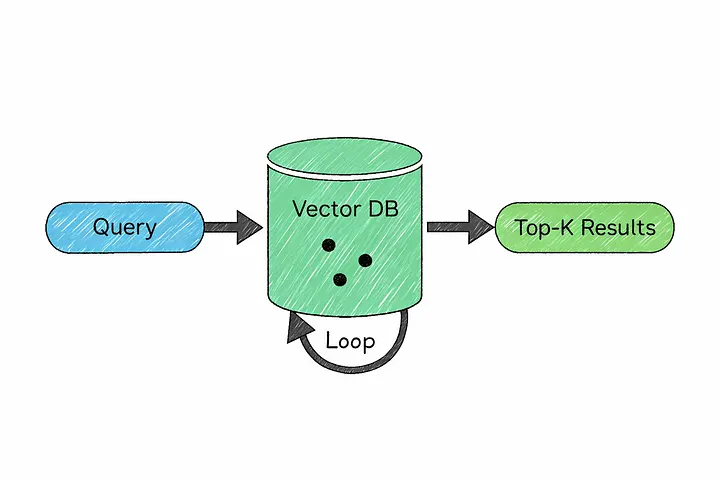
Вместо традиционного хранения текста векторная база данных хранит эмбеддинги — числовые представления смысла, о которых мы говорили ранее.
Это позволяет системе осуществлять поиск на основе семантического сходства, а не только по точным словам.
Вот как это выглядит на практике.
Сначала ваши документы разбиваются на более мелкие фрагменты (чанки), и каждый фрагмент преобразуется в эмбеддинг. Затем эти эмбеддинги сохраняются в базе данных.
Когда пользователь задает вопрос, этот запрос также преобразуется во эмбеддинг. Затем система ищет сохраненные векторы, наиболее близкие к нему — то есть наиболее схожие по смыслу — и возвращает их в качестве контекста.
Сила этого подхода заключается в том, насколько он отличается от традиционного поиска.
При поиске по точным ключевым словам вы можете упустить релевантную информацию только из-за того, что формулировка немного отличается. Но при векторном поиске система всё равно может найти нужный контент, поскольку понимает замысел, стоящий за словами, а не просто сами слова.
Именно это делает RAG настолько эффективным.
Модель не просто извлекает текст — она извлекает наиболее релевантное значение.
Существует несколько инструментов, поддерживающих такой вид поиска, в том числе системы Pinecone, Weaviate, Qdrant и даже PostgreSQL с расширениями, поддерживающими векторные запросы.
Проще говоря, векторная база данных позволяет системам искусственного интеллекта выйти за рамки сопоставления ключевых слов… и начать искать так, как думают люди.
19. ИИ-агенты
До сих пор всё, о чём мы говорили, касалось моделей, генерирующих текст.
Но что, если бы модель могла действительно что-то делать?
Именно здесь на сцену выходят ИИ-агенты.
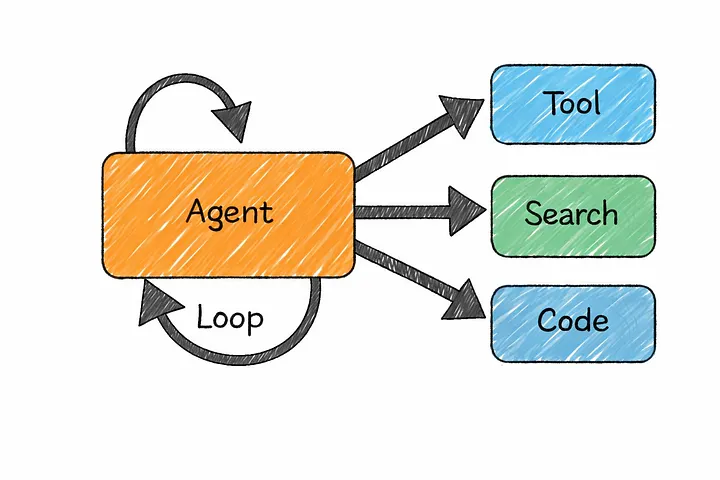
Агент искусственного интеллекта — это, по сути, языковая модель, способная не только отвечать, но и предпринимать действия. Вместо того чтобы ограничиваться ответом, он может взаимодействовать с инструментами, запускать код, искать информацию, вызывать API-интерфейсы и комбинировать эти шаги для выполнения задачи.
Другими словами, он переходит от мышления к действию.
Большинство агентов работают по простому циклу.
Они анализируют текущую ситуацию, решают, что делать дальше, предпринимают действие, а затем повторяют процесс с учётом произошедших изменений. Языковая модель находится в центре этого цикла, выступая в роли лица, принимающего решения на каждом этапе.
Представьте себе помощника-программиста, работающего над исправлением ошибки.
Он читает описание проблемы, изучает кодовую базу, выявляет возможные места сбоев, пишет исправление, запускает тесты, анализирует, что не работает, а затем корректирует решение, пока всё не заработает. Каждый шаг зависит от предыдущего, и модель постоянно адаптируется по мере поступления новой информации.
Это мощный подход, но именно здесь и возникают сложности.
На каждом этапе есть вероятность ошибки, и эти мелкие ошибки могут накапливаться. Задача, которая кажется простой, может стать ненадежной, если она предполагает принятие нескольких решений подряд.
Именно поэтому создание хороших агентов — это не просто обеспечение их функциональных возможностей. Речь идет о том, чтобы сделать их надежными.
Современные системы уделяют большое внимание планированию, проверке, повторным попыткам и самокоррекции, чтобы обеспечить бесперебойное выполнение этих многоэтапных рабочих процессов.
Проще говоря, именно агенты искусственного интеллекта превращают языковые модели в системы, способные реально действовать в реальном мире.
20. Диффузионные модели
До сих пор мы в основном говорили о тексте. А как насчёт изображений?
Именно здесь на сцену выходят диффузионные модели — технология, лежащая в основе многих современных генераторов изображений.
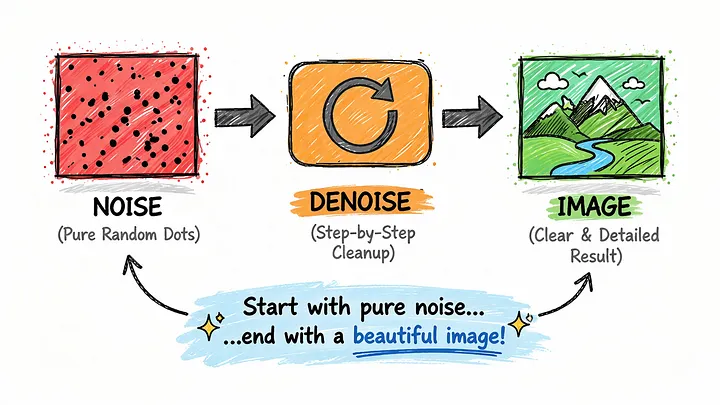
Эта идея на удивление противоречит интуиции.
Вместо того чтобы учиться напрямую создавать изображения, модель сначала учится их разрушать.
В ходе обучения реальные изображения постепенно искажаются путём многократного добавления шума, пока не превращаются в полную статику. Затем модель обучают шаг за шагом обращать этот процесс вспять, учится удалять шум и восстанавливать исходное изображение.
Когда приходит время сгенерировать что-то новое, процесс меняется на противоположный.
Вы начинаете с чистого шума.
Затем, шаг за шагом, модель очищает его, добавляя структуру, формы и детали, пока не появится полноценное изображение. Каждый шаг уточняет результат в соответствии с вашим запросом, превращая хаос в нечто осмысленное.
Название «диффузия» происходит из физики, где частицы со временем хаотично рассеиваются, как чернила, растворяющиеся в воде.
Здесь модель учится действовать в обратном направлении — как восстановить порядок из этого хаоса.
Интересно то, что эта идея больше не ограничивается только изображениями.
Тот же подход сейчас используется для генерации видео, аудио, 3D-контента и даже в таких научных областях, как проектирование молекул или прогнозирование структур белков.
Проще говоря, именно диффузионные модели позволяют ИИ брать чистый шум… и превращать его в то, что вы можете увидеть, услышать или использовать.